
虽然本文的title叫做python进阶,但其实正则表达式在其它语言(最常见的例如前端开发的javascript、以及python爬虫等)中也有运用,只不过笔者想要稍微有针对性一点。
如果你在外网期刊数据库上检索过一些文章,可以发现其检索语法和正则表达式很像。
如果你和我一样,懒得写程序,可以使用这个在线网站:https://regex101.com/。适配语言使用python即可. 当然其它也大同小异。
如果你是个python萌新,那么请放心阅读,因为我也是。
如果你是个大佬,请轻喷。
1 基础部分
首先引出普通字符的概念,也就是正则表达式中直接进行匹配的字符,例如 “原神”:
 高亮部分即为匹配成功部分
高亮部分即为匹配成功部分
但这就没办法体现出正则表达式的厉害之处了,因此我们首先介绍一下元字符:
1.1 单个字符匹配[.]
这里的 ‘.’ 是我们介绍的第一个元字符,其不代表真正的英文句点,而是代表除了换行符外的任何字符。
例如下面这个例子:
 只能匹配一个字符,这让我怎么荔枝
只能匹配一个字符,这让我怎么荔枝
你会发现,这个 ‘.’ 在原文本中匹配了不同的单个文字,例如“鸡”,“坤”。
放到python中,实现如下:
import re #regular expression
content = '''
鸡你太美
坤你太美
只因你太美
你太美
你太丑
'''#单三引号,可以直接输入换行
p = re.compile(r".你太美") #获得模式串
print(type(p))
for item in p.findall(content): #findall 返回个列表
print(item)运行结果如下:
鸡你太美
坤你太美
因你太美首先,我们需要导入 re 这个包(一般是python自带的),它是regular expression的简称,提供正则表达式的支持。
然后,content存了我们的文本串。这里使用单三引号,支持直接对内容进行多行描述。
然后,我们调用re.compile函数,里面是我们的正则表达式(这里的r是将转义字符恢复成原有字符,例如’n’不代表换行符,因为其已经被恢复成原有的反斜杠和’n’),获得一个p变量,其类型为,你可以认为是一个特殊的模式串,我们要通过这个模式串进行模式匹配。
然后该变量是类的一个实例,其拥有一个方法p.findall(),它返回的是一个列表,而在这里其内容便是我们成功匹配的子串啦!当然,待会会介绍另一个个人感觉更优的方式。
但是,如果我们也想匹配不止一个字符,该怎么办呢?
1.2 任意数量匹配[*]
上个例子中,发现我们匹配的结果“因你太美”中缺少了 ‘只’ 字,这下ikun们不满意了。辣么我们怎么办呢?
尝试一下在上面的正则表达式 ‘.你太美’ 中句号后面加个星号:

欸,这下整个“只因”都匹配进去了!
分析一下原理:既然 ‘.’ 代表任意字符,而 ‘*’ 代表任意数量,那么 ‘.*’ 不就代表任意数量的任意字符了吗?注意,这里的 ‘*’ 不代表任何字符,它是根据前一个字符而决定的。例子:
 这里的星号代表任意数量的'嘛'
这里的星号代表任意数量的'嘛'
python程序就没必要给出了。
1.3 严格大于0的数量匹配[+]
这里介绍元字符:’+’,其功能与 ‘*’ 极其相似,唯一区别是在于 ‘+’ 必须匹配大于0个的字符,而 ‘*’ 可以匹配等于0个字符:
 可以和上面的图对比一下~
可以和上面的图对比一下~
1.4 使用花括号进行匹配次数的限制
对于上面所介绍的星号和加号,我们对其匹配字符的个数加以限制,这时候我们就需要花括号了。
例如,我们想匹配准确的2个字符,可以这样:

在所要限制的字符(这里是元字符’.’)后面加个花括号,里面是你要匹配的字符个数。
当然,花括号里面也可以是一个区间:

区间中间用逗号隔开。
1.5 匹配单个或零个字符 [?]
如果我们想要匹配区间 [0,1] 个字符,除了上述花括号的写法{0,1},还可以直接使用问号 ‘?’.
具体例子就不给出了,你应该知道该怎么写。
1.6 首尾标志符 [^][$]
如果我们想让匹配的字符在一行的开头,我们可以在最前面加个首标志符 ‘^’:

如果你按照上面的模板写程序:
import re
content = '''applea
banana
aaappp'''
p = re.compile(r'^a+')
for item in p.findall(content):
print(item)可以发现其只输出了一个 ‘a’,而理论上应该还要输出 ‘aaa’,这是怎么回事呢?
原来,这里程序里的 ‘^’ 并不代表一行的开头,而是代表整个文本的开头,因此,我们需要在compile函数内修改匹配模式。
如果使用多行模式(这样每一行都有一个开头),我们可以加个参数 re.M:
import re
content = '''applea
banana
aaappp'''
p = re.compile(r'^a+',re.M)
for item in p.findall(content):
print(item)运行一下试试看!
相对应的,’$’ 则代表行尾或者文本尾,取决于你使用的模式。
2 对于字符的进阶处理
主要的元字符已经介绍完了!但是如果我们的文本内容本身就有元字符,而我们又想匹配它,该怎么办呢?
2.1 转义
转义,顾名思义,你可以理解为转化一个字符的含义。例如常见的 ‘n’ 代表换行。
而这里,我们同样使用反斜杠 ” 来进行转义。例如 ‘.’ 就代表 ‘.’ 这个字符,而 ‘?’ 就代表问号:

诶等一下下!这个括号是啥?这个 ‘|’ 又是啥?
如果你学过C,可以知道 ‘|’ 是按位或的意思,在这里你可以理解为可以同时匹配 ‘.’ 和 ‘?’。
而括号就涉及到后面要介绍的分组的概念。因此,如果你直接写代码:
import re
content = '''鸡.你太美
坤.你太美
只因.你太美
cxk?你太美
你太丑'''
p = re.compile(r'(.|?)你太美')
for item in p.findall(content):
print(item)其输出:
.
.
.
?诶?为什么不返回整个字符串,而是只返回字符,也就是括号里的东西呢?这里我们再留个悬念(逃
2.2 特定字符
我们先不管上面的问题,考虑一下如何匹配数字字符。
我们可以使用 ‘d’ 来匹配!这里的 d 代表 digit ,也就是数位的意思:

如果我们使用大写的 ‘D’ ,它就会和 ‘d’ 取补集,也就是非数位:

相对应的,’s’ 代表空白字符(space,tab,换行等),’S’ 代表非空白字符。
‘w’ 则代表任意一个文字字符,包括字母、数字、下划线。
2.3 匹配几个字符之一 []
上面的 ‘d’ 代表数字字符。但是,我们也可以使用 [0-9] 来代表数字字符。这里使用方括号来代表匹配的字符之一:
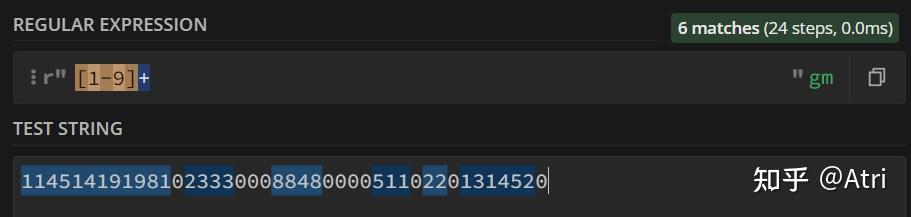
通过方括号将匹配字符限定在了[1-9],因此非0的字符皆被匹配。
如果你想匹配数字+小写字母,可以写成[0-9a-z]:

但是,如果你直接写[0-z]:
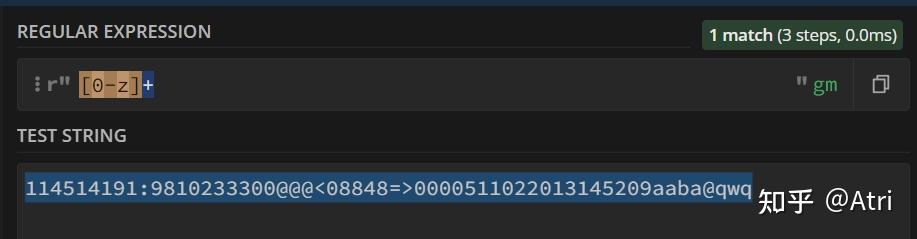
可以发现其中乱七八糟的一些字符也匹配进去了。这是因为正则表达式在这里是通过你确定的字符所代表的ASCII编码的上下界来匹配相应字符。0的ascii编码为48,z为122,而@为64,在二者之间。因此其也能被匹配。
2.4 同时匹配 [|]
上面我们提到了这个符号 ‘|’ ,它代表同时匹配几个字符之一。这个比较好理解,下面直接给出例子:
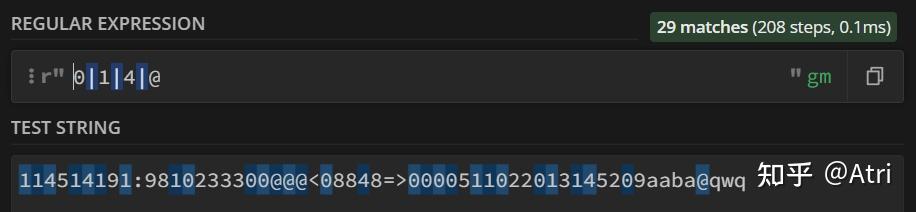
当然,如果加上分组,它便可以代表同时匹配几个子串,后面再说~
3 贪婪模式 vs 懒惰模式
这里直接给出在其它re教程中的一个练习:匹配所有的html标签。

不难想出上述的正则表达式。但是我们发现,我们div标签内的文本内容居然也被匹配了!
这是因为,我们默认的匹配模式是贪心的,也就是说,它默认匹配尽可能多的字符。因此上面的分别对应文本首尾,因为这样匹配的字数更多。
如果我们加个问号
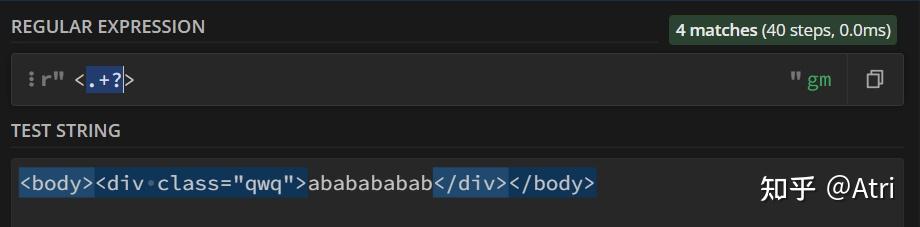
它就匹配成功了。因为匹配模式从匹配尽可能多的字符转化为匹配尽可能少的字符,也就是懒惰模式。
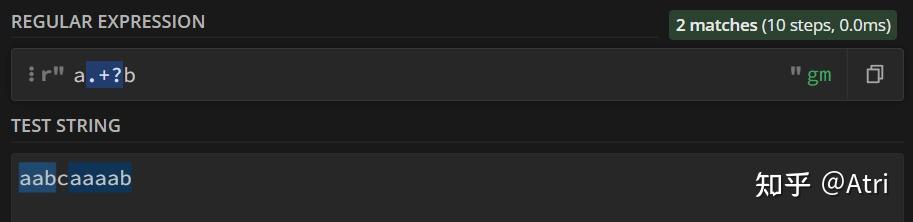
因此,当问号前面的字符是特定的字符或者 ‘.’ 时,它便是我们前面说过的用于匹配 0 or 1 个字符的元字符。而前面是 ‘*’ 或者 ‘+’ 的时候,它便代表懒惰模式!
4 用括号进行分组
假设我们要匹配文本“你太美”的前面所有字符,直接使用 “.*你太美” 是不可以的,因为它会把你太美这几个字也匹配到。
这里我们解释一下 p.findall(content) 的含义:它返回每一个成功匹配的分组的列表!
因此,我们可以加个分组的括号:

Code:
import re
content = '''鸡你太美
坤你太美
只因你太美
cxk你太美
你太丑'''
p = re.compile(r'(.+)你太美',re.M)
for item in p.findall(content):
print(item)Output:
鸡
坤
只因
cxk可以发现成功将 “你太美” 分了出去!
当然,分组一般可以多次使用。例如我们每一行有个个人信息,需要将姓名和电话号码提取出:

Code:
import re
content = '''菜虚坤,电话号码:11451419198
签哥,电话号码:23333333333
池答辩,电话号码:02020202022'''
p = re.compile(r'^(.{2,3}),电话号码:(d{11})',re.M)
for item in p.findall(content):
print(item)Output:
('菜虚坤', '11451419198')
('签哥', '23333333333')
('池答辩', '02020202022')对于每一行,返回一个列表。
但是,如果我们想返回整个行的内容,该怎么办呢?
很明显,直接输出就好了(逃
如果只提取关键信息:
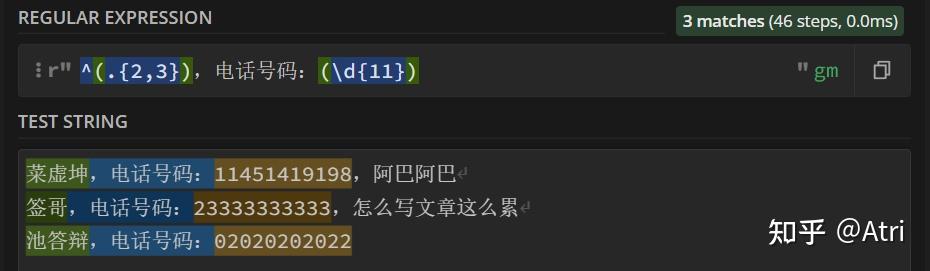
这时候我们需要用到另一个函数:finditer()。它是通过迭代的方式,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回:
import re
content = '''菜虚坤,电话号码:11451419198,阿巴阿巴
签哥,电话号码:23333333333,怎么写文章这么累
池答辩,电话号码:02020202022'''
p = re.compile(r'^(.{2,3}),电话号码:(d{11})',re.M)
print(p.finditer(content))
for item in p.finditer(content):
print(item.group(),item.group(1),item.group(2))Output:
菜虚坤,电话号码:11451419198 菜虚坤 11451419198
签哥,电话号码:23333333333 签哥 23333333333
池答辩,电话号码:02020202022 池答辩 02020202022这里每一个item的group代表你每一个分组内的字符串。默认的group()或者group(0)代表整个大分组,也就是整个所匹配的字符串。
因此,对于 2.1 的例子,我们可以使用 p.finditer(content) 返回的迭代器所对应每一个迭代变量的group()方法来提取每一个完整匹配的字符串。
5 分割字符串 split()
如果你打过ACM,那么你应该知道,使用python进行输入的时候,常常会搭配split方法:
A = input().split(' ')一样地,split里面可以是一个正则表达式,例如我们想把一段英文中的所有单词提取出来:

Code:
import re
content = '''I want to play galgame, What about you? emmm. '''
p = re.compile(r's*[.,?s]s*' ,re.M)
lis = p.split(content)
print(lis)Output:
['I', 'want', 'to', 'play', 'galgame', 'What', 'about', 'you', 'emmm', '']这里的正则表达式代表 . , ? 和多余的空白字符,以此为基准进行分割,得到正文单词。
6 个人练习:IP地址匹配
假设ip地址的每一位在0-255之间,共四位,由3个句点隔开,无前导零。

这里的b代表和相邻的文本进行分隔。
稍微分析一下,这里便涉及了分组和 ‘|’ 符号的共同使用。在这里你可以把这里的 ‘|’ 号看作或的关系,也就是许许多多的括号(25[0-5])|(2[0-4]d)|(1d{2})|([1-9]d)|(d)中间用竖线隔开,代表可以同时匹配这么多分组内的其中一个分组所代表的串。对于上面每一个分组内的含义:
第一个代表区间[250,255],第二个代表区间[200,249],第三个代表[100,199],第四个代表[10,99],第五个代表[0,9],合起来便是[0-255]。注意前导0。
当然,括号还可以嵌套使用,我们将上面整体用括号分为一个大组,然后和转义字符 ‘.’,便代表ip地址的一位加上句点:XXX.
然后我们用{3}让它复制三遍,最后把数字部分复制到结尾,就大功告成了!
Code:
import re
content = '''114.514.191.810
255.255.025.255
245.146.192.68
255.255.255:255
0.0.0.1
145.255.148.72
72.162.11.3
255.256.255.249'''
p = re.compile(r'b(((25[0-5])|(2[0-4]d)|(1d{2})|([1-9]d)|(d)).){3}'
r'((25[0-5])|(2[0-4]d)|(1d{2})|([1-9]d)|(d))b',re.M)
for item in p.finditer(content):
print(item.group())Output:
245.146.192.68
0.0.0.1
145.255.148.72
72.162.11.37 结语
以上是 python with re 的最基础的内容,笔者花费几个小时自学的。
不得不说,在ACM打铁和绩点爆炸的压力下还能摸鱼学点其它东西,也算是一种勇气吧。
以后可能也会做点其它的python笔记,毕竟我的python用的太少。











