
第7章MySQL InnoDB集群
目录
-
7.1 InnoDB集群要求
-
7.2 InnoDB集群限制
-
7.3 InnoDB集群的用户帐户
-
7.4 部署生产InnoDB集群
-
7.5 配置InnoDB集群
-
7.6 保护InnoDB集群
-
7.7 监控InnoDB集群
-
7.8 恢复和重启InnoDB集群
-
7.9 修改或解散InnoDB集群
-
7.10 升级InnoDB集群
MySQL InnoDB Cluster为MySQL提供了完整的高可用性解决方案。通过使用MySQL Shell附带的 AdminAPI ,您可以轻松配置和管理一组至少三个 MySQL 服务器实例,以充当 InnoDB 集群。
InnoDB Cluster 中的每个 MySQL 服务器实例都运行 MySQL Group Replication,它提供了在 InnoDB Cluster 中复制数据的机制,并具有内置故障转移功能。AdminAPI 消除了在 InnoDB 集群中直接使用组复制的需要,但有关更多信息,请参阅 组复制,其中解释了详细信息。从 MySQL 8.0.27 开始,您还可以设置 InnoDB ClusterSet(请参阅 第 8 章,MySQL InnoDB ClusterSet),通过将主 InnoDB Cluster 与其位于备用位置(例如不同位置)的一个或多个副本链接起来,为 InnoDB Cluster 部署提供容灾能力。数据中心。
MySQL Router可以根据您部署的集群自动配置自身,将客户端应用程序透明地连接到服务器实例。如果服务器实例发生意外故障,集群会自动重新配置。在默认的单主模式下,InnoDB集群有一个读写服务器实例——主实例。多个辅助服务器实例是主服务器实例的副本。如果主服务器发生故障,辅助服务器将自动提升为主服务器角色。MySQL Router 检测到这一点并将客户端应用程序转发到新的主路由器。高级用户还可以将集群配置为具有多个主节点。
下图显示了这些技术如何协同工作的概述:
图7.1 InnoDB集群概览

重要的
InnoDB Cluster 不提供对 MySQL NDB Cluster 的支持。NDB Cluster 依赖于NDB存储引擎以及一些特定于 NDB Cluster 的程序,这些程序未随 MySQL Server 8.0 提供; NDB仅作为 MySQL NDB Cluster 发行版的一部分提供。此外,MySQL Server 8.0 附带的MySQL 服务器二进制文件 ( **mysqld ) 不能与 NDB Cluster 一起使用。**有关 MySQL NDB Cluster 的更多信息,请参阅MySQL NDB Cluster 8.0。 使用 InnoDB 的 MySQL 服务器与 NDB Cluster 相比InnoDB,提供了有关存储引擎和存储引擎之间差异的信息 NDB。
7.1 InnoDB集群要求
在安装 InnoDB Cluster 的生产部署之前,请确保您要使用的服务器实例满足以下要求。
-
InnoDB Cluster 使用组复制,因此您的服务器实例必须满足相同的要求。请参阅 组复制要求。AdminAPI 提供了
dba.checkInstanceConfiguration()验证实例是否满足组复制要求的方法,以及dba.configureInstance()配置实例以满足要求的方法。笔记
使用沙盒部署时,实例将被配置为自动满足这些要求。
-
用于组复制的数据以及用于 InnoDB Cluster 的数据必须存储在
InnoDB事务存储引擎中。使用其他存储引擎(包括临时MEMORY存储引擎)可能会导致组复制出错。InnoDB在将实例与组复制和 InnoDB 集群一起使用之前,转换其他存储引擎中的任何表以供使用 。您可以通过在服务器实例上设置系统变量来阻止使用其他存储引擎disabled_storage_engines,例如:disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
-
设置集群时,任何服务器实例上都不能有入站复制通道。正在采用的复制组上允许使用组复制自动创建的通道(
group_replication_applier和 )。group_replication_recovery除了使用 AdminAPI 管理的通道之外,InnoDB Cluster 不支持手动配置的异步复制通道。如果您要将现有复制拓扑迁移到 InnoDB 集群部署,并且需要在设置过程中暂时跳过此验证,则可以force在创建集群时使用该选项来绕过它。 -
group_replication_tls_source不得设置为mysql_admin. -
必须在要与 InnoDB Cluster 一起使用的任何实例上启用性能架构。
-
MySQL Shell 用于配置服务器以便在 InnoDB Cluster 中使用的配置脚本需要访问 Python。在 Windows 上,MySQL Shell 包含 Python,无需用户配置。在 Unix 上,Python 必须作为 shell 环境的一部分存在。要检查您的系统是否已正确配置 Python,请执行以下操作:
$ /usr/bin/env python
如果 Python 解释器启动,则无需执行进一步操作。如果上一个命令失败,请在您选择的 Python 二进制文件之间创建软链接
/usr/bin/python。有关详细信息,请参阅 支持的语言。 -
server_id从版本 8.0.17 开始,实例必须在 InnoDB Cluster 中 使用唯一的 。当您使用该 操作时,如果 of已被集群中的实例使用,则该操作将失败并出现错误。*Cluster*.addInstance(*instance*)server_idinstance -
从版本 8.0.23 开始,实例应配置为使用并行复制应用程序。请参见 第 7.5.6 节 “配置并行复制应用程序”。
-
在为InnoDB Cluster配置实例的过程中,配置了使用实例所需的大部分系统变量。但AdminAPI没有配置
transaction_isolation系统变量,这意味着它默认为REPEATABLE READ. 这不会影响单主集群,但如果您使用多主集群,那么除非您依赖REPEATABLE READ应用程序中的语义,否则我们建议使用READ COMMITTED隔离级别。请参阅组复制限制。 -
实例的相关配置选项,特别是组复制配置选项,必须位于单个选项文件中。InnoDB Cluster 仅支持服务器实例的单个选项文件,不支持使用
--defaults-extra-file选项指定附加选项文件。对于使用实例选项文件的任何 AdminAPI 操作,必须指定主文件。如果要对与 InnoDB Cluster 无关的配置选项使用多个选项文件,则必须手动配置这些文件,并确保考虑多个选项文件使用的优先级规则正确更新它们,并确保相关设置InnoDB Cluster 不会被额外的无法识别的选项文件中的选项错误地覆盖。
7.2 InnoDB集群限制
本节介绍 InnoDB Cluster 的已知限制。由于 InnoDB Cluster 使用组复制,您还应该了解其限制,请参阅 组复制限制。
-
重要的
由于元数据查询中出现错误,MySQL Shell 8.0.27 无法用于管理运行 MySQL Server 8.0.25 的 InnoDB Cluster。要解决此问题,请在 InnoDB 集群成员实例上将 MySQL Server 升级到 8.0.26 或 8.0.27 版本,然后再将 MySQL Shell 8.0.27 与集群一起使用。该问题将在 MySQL Shell 8.0.28 中得到修复。
-
InnoDB Cluster不管理手动配置的异步复制通道。组复制和 AdminAPI 不能确保异步复制仅在主服务器上处于活动状态,并且状态不会跨实例复制。这可能会导致复制不再起作用的各种情况,并可能导致脑裂。仅 InnoDB ClusterSet 支持一个 InnoDB Cluster 与另一个 InnoDB ClusterSet 之间的复制,InnoDB ClusterSet 从 MySQL 8.0.27 开始提供,并管理从活动主读写 InnoDB Cluster 到多个只读副本集群的复制。有关该解决方案的信息,请参阅第 8 章,MySQL InnoDB ClusterSet。
-
InnoDB Cluster 旨在部署在局域网中。在广域网上部署单个 InnoDB Cluster 对写入性能有显着影响。稳定且低延迟的网络对于 InnoDB Cluster 成员服务器使用底层组复制技术相互通信以达成事务共识非常重要。然而,InnoDB ClusterSet 被设计为跨多个数据中心部署,每个 InnoDB Cluster 都位于单个数据中心中,并且异步复制通道将它们链接起来。有关该解决方案的信息,请参阅第 8 章,MySQL InnoDB ClusterSet。
-
对于 AdminAPI 操作,您只能使用 TCP/IP 连接和经典 MySQL 协议连接到 InnoDB Cluster 中的服务器实例。AdminAPI 操作不支持使用 Unix 套接字和命名管道,并且 AdminAPI 操作不支持使用 X 协议。同样的限制也适用于服务器实例本身之间的连接。
笔记
客户端应用程序可以使用 X 协议、Unix 套接字和命名管道来连接到 InnoDB 集群中的实例。这些限制仅适用于使用 AdminAPI 命令的管理操作以及实例之间的连接。
-
AdminAPI 和 InnoDB Cluster 支持使用运行 MySQL Server 5.7 的实例。但是,这些实例还有其他限制,并且所描述的某些功能在您使用它们时不适用。 第 6.2.1 节“使用运行 MySQL 5.7 的实例”列出了其他限制。
-
使用多主模式时,不支持针对同一对象但在不同服务器上发出的并发数据定义语句和数据操作语句。在对对象发出数据定义语言 (DDL) 语句期间,从不同的服务器实例对同一对象发出并发数据操作语言 (DML) 存在无法检测到在不同实例上执行的冲突 DDL 的风险。有关详细信息,请参阅 组复制限制。
7.3 InnoDB集群的用户帐户
InnoDB Cluster 中的成员服务器使用三种类型的用户帐户。一个 InnoDB Cluster 服务器配置帐户用于配置集群的服务器实例。集群搭建完成后,可以创建一个或多个InnoDB Cluster管理员账户,供管理员管理服务器实例。可以为 MySQL Router 实例创建一个或多个 MySQL Router 帐户以连接到集群。每个用户帐户必须存在于 InnoDB Cluster 中的所有成员服务器上,并且具有相同的用户名和密码。
-
InnoDB Cluster服务器配置帐户
该帐户用于创建和配置InnoDB Cluster的成员服务器。每台成员服务器只有一个服务器配置帐户。集群中的每台成员服务器必须使用相同的用户帐户名和密码。您可以使用
root服务器上的帐户来实现此目的,但如果这样做,root集群中每个成员服务器上的帐户必须具有相同的密码。出于安全原因,不建议这样做。首选方法是使用dba.configureInstance()带有clusterAdmin选项的命令创建 InnoDB Cluster 服务器配置帐户。为了获得更好的安全性,请在交互式提示符处指定密码,否则使用 选项指定密码clusterAdminPassword。在将成为 InnoDB 集群一部分的每个服务器实例(您连接到创建集群的实例以及将加入集群的实例)上以相同的方式使用相同的用户名和密码创建相同的帐户在那之后。该dba.configureInstance()命令自动授予帐户所需的权限。如果您愿意,可以手动设置该帐户,并授予其 手动配置 InnoDB 集群管理员帐户中列出的权限。除了完整的 MySQL 管理员权限之外,该帐户还需要对 InnoDB Cluster 元数据表具有完整的读写权限。您使用该dba.configureInstance()操作创建的 InnoDB Cluster 服务器配置帐户不会复制到 InnoDB Cluster 中的其他服务器。MySQL Shell 禁用该dba.configureInstance()操作的二进制日志记录。这意味着您必须在每个服务器实例上单独创建帐户。 -
InnoDB集群管理员帐户
完成配置过程后,这些帐户可用于管理 InnoDB Cluster。您可以设置多个。每个帐户必须存在于 InnoDB Cluster 中的每个成员服务器上,并具有相同的用户名和密码。要为 InnoDB ClusterSet 部署创建 InnoDB Cluster 管理员帐户,请
*cluster*.setupAdminAccount()在将所有实例添加到该集群后发出命令。该命令使用您指定的用户名和密码创建一个帐户,并具有所有必需的权限。用于创建帐户的事务*cluster*.setupAdminAccount()将写入二进制日志并发送到集群中的所有其他服务器实例以在其上创建帐户。笔记如果主 InnoDB Cluster 是在 MySQL Shell 8.0.20 之前的版本中设置的,则该*cluster*.setupAdminAccount()命令可能已与update更新 InnoDB Cluster 服务器配置帐户的权限选项一起使用。这是不写入二进制日志的命令的特殊用途。 -
MySQL 路由器帐户
MySQL Router 使用这些帐户连接到 InnoDB 集群中的服务器实例。您可以设置多个。每个帐户必须存在于 InnoDB Cluster 中的每个成员服务器上,并具有相同的用户名和密码。创建 MySQL Router 帐户的过程与创建 InnoDB Cluster 管理员帐户的过程相同,但使用命令
*cluster*.setupRouterAccount()。有关创建或升级 MySQL Router 帐户的说明,请参阅 第 6.10.2 节 “配置 MySQL Router 用户”。
手动配置InnoDB集群管理员帐户
如果要手动配置 InnoDB Cluster 管理用户,该用户需要此处列出的权限,所有权限都带有GRANT OPTION.
笔记
此权限列表基于 MySQL Shell 的当前版本。不同版本之间的权限可能会发生变化。因此,建议的设置管理帐户的方法是使用 dba.configureInstance()or *cluster*.setupAdminAccount() 操作。
重要的
用于管理 InnoDB Cluster、InnoDB ClusterSet 或 InnoDB ReplicaSet 部署的每个帐户必须存在于部署中的所有成员服务器实例上,并且具有相同的用户名和密码。
-
RELOAD、SHUTDOWN、PROCESS、FILE、 、SELECT、 、 、 、 、 、 、 、 、SUPER和REPLICATION SLAVE的REPLICATION CLIENT*REPLICATION_APPLIER.CREATE USER*SYSTEM_VARIABLES_ADMIN上PERSIST_RO_VARIABLES_ADMIN的 全局 权限 。BACKUP_ADMINCLONE_ADMINEXECUTE笔记
SUPER包括以下必需的权限:SYSTEM_VARIABLES_ADMIN、SESSION_VARIABLES_ADMIN、REPLICATION_SLAVE_ADMIN、GROUP_REPLICATION_ADMIN、REPLICATION_SLAVE_ADMIN、ROLE_ADMIN。 -
mysql_innodb_cluster_metadata.*、mysql_innodb_cluster_metadata_bkp.*和 的 架构特定权限mysql_innodb_cluster_metadata_previous.*为ALTER,ALTER ROUTINE,CREATE,CREATE ROUTINE,CREATE TEMPORARY TABLES,CREATE VIEW,DELETE,DROP,EVENT,EXECUTE,INDEX,INSERT,LOCK TABLES,REFERENCES,SHOW VIEW,TRIGGER,UPDATE; 对于mysql.*是INSERT,UPDATE,DELETE.
如果只需要读取操作,例如创建用于监控目的的用户,则可以使用权限更受限制的帐户。授予用户 *your_user*监控 InnoDB Cluster 问题所需的权限:
GRANT SELECT ON mysql_innodb_cluster_metadata.* TO your_user@'%';
GRANT SELECT ON mysql.slave_master_info TO your_user@'%';
GRANT SELECT ON mysql.user TO your_user@'%';
GRANT SELECT ON performance_schema.global_status TO your_user@'%';
GRANT SELECT ON performance_schema.global_variables TO your_user@'%';
GRANT SELECT ON performance_schema.replication_applier_configuration TO your_user@'%';
GRANT SELECT ON performance_schema.replication_applier_status TO your_user@'%';
GRANT SELECT ON performance_schema.replication_applier_status_by_coordinator TO your_user@'%';
GRANT SELECT ON performance_schema.replication_applier_status_by_worker TO your_user@'%';
GRANT SELECT ON performance_schema.replication_connection_configuration TO your_user@'%';
GRANT SELECT ON performance_schema.replication_connection_status TO your_user@'%';
GRANT SELECT ON performance_schema.replication_group_member_stats TO your_user@'%';
GRANT SELECT ON performance_schema.replication_group_members TO your_user@'%';
GRANT SELECT ON performance_schema.threads TO your_user@'%' WITH GRANT OPTION;
欲了解更多信息,请参阅 账户管理报表。
InnoDB Cluster创建的内部用户帐户
作为使用组复制的一部分,InnoDB Cluster 创建内部恢复用户,以启用集群中服务器之间的连接。这些用户是集群内部的,生成的用户的用户名遵循 的命名方案 ,其中对于实例是唯一的。在 8.0.17 之前的版本中,生成的用户的用户名遵循命名方案 . mysql_innodb_cluster_*server_id*@%server_idmysql_innodb_cluster_r[*10_numbers*]
这些内部用户使用的主机名设置为“%”。在 v8.0.17 之前,ipAllowlist受影响的主机名行为是通过在 ipAllowlist. 有关详细信息,请参阅 创建服务器白名单。
每个内部用户都有一个随机生成的密码。从版本 8.0.18 开始,AdminAPI 允许您更改内部用户生成的密码。请参阅 重置恢复帐户密码。随机生成的用户将获得以下奖励:
GRANT REPLICATION SLAVE ON *.* to internal_user;
内部用户帐户在种子实例上创建,然后复制到集群中的其他实例。内部用户有:
- 通过发出创建新集群时生成
dba.createCluster() - 通过发出以下命令将新实例添加到集群时生成
*Cluster*.addInstance() - 使用主要成员使用的身份验证插件生成
在 v8.0.17 之前,ipAllowlist导致 *Cluster*.rejoinInstance() 删除旧的内部用户并生成新的用户,而不是重用它们。
有关组复制所需的内部用户的更多信息,请参阅 分布式恢复的用户凭据。
重置恢复帐户密码
从版本 8.0.18 开始,您可以使用该 *Cluster*.resetRecoveryAccountsPassword() 操作重置 InnoDB Cluster 创建的内部恢复帐户的密码,例如遵循自定义密码生命周期策略。使用该 *Cluster*.resetRecoveryAccountsPassword() 操作重置集群使用的所有内部恢复帐户的密码。该操作为每个在线实例上的内部恢复帐户设置一个新的随机密码。如果无法到达实例,则操作失败。您可以使用force可以选择忽略此类实例,但不建议这样做,并且在使用此操作之前使实例重新联机会更安全。此操作仅适用于InnoDB Cluster创建的密码,不能用于更新手动创建的密码。
笔记
执行此操作的用户必须具有所有必需的管理权限,特别是 CREATE USER为了确保无论需要密码验证的策略如何,都可以更改恢复帐户的密码。换句话说,与 password_require_current 系统变量是否启用无关
7.4 部署生产InnoDB集群
- 7.4.1 预检查InnoDB集群使用情况的实例配置
- 7.4.2 配置生产实例以供 InnoDB 集群使用
- 7.4.3 创建InnoDB集群
- 7.4.4 添加实例到InnoDB集群
- 7.4.5 配置InnoDB集群端口
- 7.4.6 将 MySQL 克隆与 InnoDB 集群结合使用
- 7.4.7 采用组复制部署
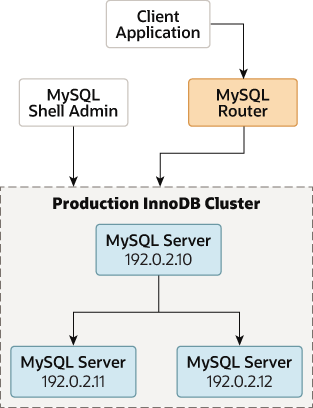
在生产环境中工作时,组成 InnoDB 集群的 MySQL 服务器实例作为网络的一部分运行在多台主机上,而不是如第 6.8 节 “AdminAPI MySQL 沙箱”中所述的在单台机器上运行。在继续执行这些说明之前,您必须将所需的软件安装到要作为服务器实例添加到集群的每台计算机上,请参阅第 6.2 节 “安装 AdminAPI 软件组件”。
下图说明了您在本节中使用的场景:
图 7.2 生产部署
重要的
与沙盒部署不同,沙盒部署中所有实例都本地部署到 AdminAPI 具有本地文件访问权限并可以保留配置更改的一台计算机,而对于生产部署,您必须保留实例上的所有配置更改。如何执行此操作取决于实例上运行的 MySQL 版本,请参阅 第 6.2.4 节 “持久设置”。
要将服务器的连接信息传递给 AdminAPI,请使用类似 URI 的连接字符串或数据字典;请参阅 使用类似 URI 的字符串或键值对连接到服务器。在本文档中,显示了类似 URI 的字符串。
本节假设您拥有:
- 将MySQL 组件 安装到您的实例
- 安装了MySQL Shell,可以通过 指定实例进行连接
- 创建了合适的 管理用户
7.4.1 预检查InnoDB集群使用情况的实例配置
在从服务器实例创建生产部署之前,您需要检查每个实例上的 MySQL 是否配置正确。该dba.configureInstance() 函数将其作为配置实例的一部分执行此操作,但您可以选择使用该 函数。这将检查实例是否满足第 7.1 节“InnoDB 集群要求”中列出的要求, 而无需更改实例上的任何配置。这不会检查实例上的任何数据,请参阅 检查实例状态以了解更多信息。 dba.checkInstanceConfiguration(*instance*)
用于连接到实例的用户必须具有适当的权限,例如在 手动配置 InnoDB 集群管理员帐户中配置的权限。下面演示了在运行的 MySQL Shell 中发出此命令:
mysql-js> dba.checkInstanceConfiguration('icadmin@ic-1:3306')
Please provide the password for 'icadmin@ic-1:3306': ***
Validating MySQL instance at ic-1:3306 for use in an InnoDB cluster...
This instance reports its own address as ic-1
Clients and other cluster members will communicate with it through this address by default.
If this is not correct, the report_host MySQL system variable should be changed.
Checking whether existing tables comply with Group Replication requirements...
No incompatible tables detected
Checking instance configuration...
Some configuration options need to be fixed:
+--------------------------+---------------+----------------+--------------------------------------------------+
| Variable | Current Value | Required Value | Note |
+--------------------------+---------------+----------------+--------------------------------------------------+
| enforce_gtid_consistency | OFF | ON | Update read-only variable and restart the server |
| gtid_mode | OFF | ON | Update read-only variable and restart the server |
| server_id | 1 | | Update read-only variable and restart the server |
+--------------------------+---------------+----------------+--------------------------------------------------+
Please use the dba.configureInstance() command to repair these issues.
{
"config_errors": [
{
"action": "restart",
"current": "OFF",
"option": "enforce_gtid_consistency",
"required": "ON"
},
{
"action": "restart",
"current": "OFF",
"option": "gtid_mode",
"required": "ON"
},
{
"action": "restart",
"current": "1",
"option": "server_id",
"required": ""
}
],
"status": "error"
}
对您计划用作集群一部分的每个服务器实例重复此过程。运行后生成的报告 dba.checkInstanceConfiguration()提供有关在 InnoDB 集群部署中使用实例所需的任何配置更改的信息。报告 部分 action中的字段 告诉您实例上的 MySQL 是否需要重新启动才能检测对配置文件所做的任何更改。config_error
7.4.2 配置生产实例以供 InnoDB 集群使用
AdminAPI 提供了 dba.configureInstance()检查实例是否适合 InnoDB Cluster 使用的功能,并在发现任何与 InnoDB Cluster 不兼容的设置时配置实例。您对实例运行该 dba.configureInstance()命令,它会检查使该实例能够用于 InnoDB Cluster 使用所需的所有设置。如果实例不需要更改配置,则无需修改实例的配置,命令 dba.configureInstance()输出确认该实例已准备好供 InnoDB Cluster 使用。
如果需要进行任何更改以使实例与 InnoDB Cluster 兼容,则会显示不兼容设置的报告,并且您可以选择让命令对实例的选项文件进行更改。根据 MySQL Shell 连接到实例的方式以及实例上运行的 MySQL 版本,您可以通过将这些更改保存到远程实例的选项文件来使这些更改永久化,请参阅第 6.2.4 节 “持久设置”。
不支持持久配置更改的实例自动要求您在本地配置实例,请参阅使用 来配置实例 dba.configureLocalInstance()。或者,您可以手动更改实例的选项文件,请参阅使用选项文件了解更多信息。无论您以何种方式进行配置更改,您可能都必须重新启动 MySQL 以确保检测到配置更改。
该命令的语法dba.configureInstance() 是:
dba.configureInstance([instance][, options])
其中*instance是实例定义,options*是带有用于配置操作的附加选项的数据字典。该操作返回有关结果的描述性文本消息。
定义*instance*是实例的连接数据。例如:
dba.configureInstance('user@example:3306')
有关更多信息,请参阅 使用类似 URI 的字符串或键值对连接到服务器。如果目标实例已经属于 InnoDB Cluster,则会生成错误并且该过程失败。
选项字典可以包含以下内容:
mycnfPath– 实例的MySQL选项文件的路径。请注意,InnoDB Cluster 仅支持服务器实例的单个选项文件,并且不支持使用选项--defaults-extra-file来指定附加选项文件。对于使用实例选项文件的任何 AdminAPI 操作,必须指定主文件。outputMycnfPath– 写入实例的 MySQL 选项文件的替代输出路径。password– 连接使用的密码。clusterAdmin– 要创建的InnoDB Cluster管理员用户的名称。支持的格式是标准 MySQL 帐户名格式。支持用户名和主机名的标识符或字符串。默认情况下,如果不加引号,则假定输入是字符串。请参阅第 6.4 节“为 AdminAPI 创建用户帐户”。clusterAdminPassword– 使用创建的 InnoDB Cluster 管理员帐户的密码clusterAdmin。尽管您可以使用此选项进行指定,但这存在潜在的安全风险。如果您不指定此选项,但指定了该clusterAdmin选项,系统会在交互式提示中提示您输入密码。clearReadOnly– 用于确认super_read_only应设置为关闭的布尔值,请参阅 超级只读模式下的实例配置。此选项已弃用,并计划在未来版本中删除。interactive– 一个布尔值,用于在命令执行中禁用交互式向导,以便不向用户提供提示,也不显示确认提示。restart– 一个布尔值,用于指示应执行目标实例的远程重新启动以完成操作。
尽管连接密码可以包含在实例定义中,但这是不安全的,不建议这样做。使用 MySQL Shell 第 4.4 节“可插入密码存储”来安全地存储实例密码。
一旦dba.configureInstance()针对实例发出该命令,该命令就会检查该实例的设置是否适合 InnoDB Cluster 使用。将显示一个报告,其中显示 InnoDB Cluster 所需的设置。如果实例不需要对其设置进行任何更改,您可以在 InnoDB 集群中使用它,并可以继续 第 7.4.3 节 “创建 InnoDB 集群”。如果实例的设置对于 InnoDB Cluster 使用无效,该 dba.configureInstance()命令将显示需要修改的设置。在配置实例之前,系统会提示您确认表中显示的更改,其中包含以下信息:
Variable– 无效的配置变量。Current Value– 无效配置变量的当前值。Required Value– 配置变量所需的值。
如何继续取决于实例是否支持持久设置,请参阅 第 6.2.4 节 “持久设置”。当 dba.configureInstance()针对当前正在运行 MySQL Shell 的 MySQL 实例(即本地实例)发出 时,它会尝试自动配置该实例。当 dba.configureInstance()针对远程实例发出 时,如果该实例支持自动持久配置更改,您可以选择执行此操作。如果远程实例不支持保存更改以将其配置为 InnoDB Cluster 使用,则必须在本地配置该实例。请参阅 使用配置实例 dba.configureLocalInstance()。
dba.configureInstance()一般来说,配置选项文件 后不需要重新启动实例 ,但对于某些特定设置可能需要重新启动。该信息显示在发布后生成的报告中dba.configureInstance()。如果实例支持该 RESTART语句,MySQL Shell 可以关闭然后启动该实例。这可确保 mysqld 检测到对实例选项文件所做的更改。有关详细信息,请参阅 RESTART。
笔记
执行RESTART 语句后,与实例的当前连接将丢失。如果启用自动重新连接,则服务器重新启动后将重新建立连接。否则,必须手动重新建立连接。
该dba.configureInstance()方法验证是否有合适的用户可用于集群使用,该用户用于集群成员之间的连接,请参阅第 6.4 节 “为 AdminAPI 创建用户帐户”。
如果您不指定用户来管理集群,则在交互模式下,向导允许您选择以下选项之一:
- 为root用户启用远程连接,不建议在生产环境中使用
- 创建一个新用户
- 没有自动配置,这种情况下需要手动创建用户
提示
如果实例有 super_read_only=ON,那么您可能需要确认 AdminAPI 可以设置 super_read_only=OFF。更多信息请参见 超级只读模式实例配置。
配置实例 dba.configureLocalInstance()
不支持自动持久配置更改的实例(请参阅 第 6.2.4 节“持久设置”)要求您连接到服务器、运行 MySQL Shell、本地连接到实例并发出 dba.configureLocalInstance(). 这使得 MySQL Shell 能够在对远程实例运行以下命令后修改实例的选项文件:
dba.configureInstance()dba.createCluster()*Cluster*.addInstance()*Cluster*.removeInstance()*Cluster*.rejoinInstance()
重要的
未能将配置更改保留到实例的选项文件可能会导致实例在下次重新启动后无法重新加入集群。
实例的相关配置选项,特别是组复制配置选项,必须位于单个选项文件中。InnoDB Cluster 仅支持服务器实例的单个选项文件,不支持使用选项 --defaults-extra-file指定附加选项文件。对于使用实例选项文件的任何 AdminAPI 操作,必须指定主文件。
持久保存配置更改的推荐方法是登录到远程计算机(例如使用 SSH),以 root 用户身份运行 MySQL Shell,然后连接到本地 MySQL 服务器。例如,使用 --uri选项连接到本地*instance*:
$> sudo -i mysqlsh --uri=instance
或者使用\connect命令登录本地实例。然后发出 ,其中是本地实例的连接信息,以保留对本地实例的选项文件所做的任何更改。 dba.configureInstance(*instance*)instance
mysql-js> dba.configureLocalInstance('icadmin@ic-2:3306')
对集群中不支持自动持久配置更改的每个实例重复此过程。例如,如果您向不支持自动持久化配置更改的集群添加 2 个实例,则必须在实例重新启动之前连接到每台服务器并持久化 InnoDB Cluster 所需的配置更改。同样,如果您修改集群结构,例如更改实例数量,则需要对每个服务器实例重复此过程,以相应地更新集群中每个实例的 InnoDB Cluster 元数据。
超级只读模式实例配置
每当组复制停止时,该 super_read_only变量都会设置为ON以确保不会对实例进行写入。当您尝试通过以下 AdminAPI 命令使用此类实例时,您可以选择 super_read_only=OFF在实例上进行设置:
dba.configureInstance()dba.configureLocalInstance()dba.dropMetadataSchema()
当 AdminAPI 遇到一个实例时 super_read_only=ON,在交互模式下您可以选择设置 super_read_only=OFF。例如:
mysql-js> var myCluster = dba.dropMetadataSchema()
Are you sure you want to remove the Metadata? [y/N]: y
The MySQL instance at 'localhost:3310' currently has the super_read_only system
variable set to protect it from inadvertent updates from applications. You must
first unset it to be able to perform any changes to this instance.
For more information see:
https://dev.mysql.com/doc/refman/en/server-system-variables.html#sysvar_super_read_only.
Do you want to disable super_read_only and continue? [y/N]: y
Metadata Schema successfully removed.
显示实例的当前活动会话数。您必须确保任何应用程序都不会无意中写入实例。通过回答,y您确认 AdminAPI 可以写入实例。如果列出的实例有多个打开的会话,请在允许 AdminAPI 设置之前务必小心 super_read_only=OFF。
7.4.3 创建InnoDB集群
准备好实例后,使用该 dba.createCluster()函数创建集群,并使用 MySQL Shell 连接到的实例作为集群的种子实例。种子实例将复制到您添加到集群中的其他实例,使它们成为种子实例的副本。在此过程中,ic-1 实例用作种子。当您发出命令时, MySQL Shell 会为连接到 MySQL Shell 当前全局会话的服务器实例创建一个经典 MySQL 协议会话。例如,要创建一个名为 的簇 ,并将返回的簇分配给名为 的变量: dba.createCluster(*name*)testClustercluster
mysql-js> var cluster = dba.createCluster('testCluster')
Validating instance at icadmin@ic-1:3306...
This instance reports its own address as ic-1
Instance configuration is suitable.
Creating InnoDB cluster 'testCluster' on 'icadmin@ic-1:3306'...
Adding Seed Instance...
Cluster successfully created. Use Cluster.addInstance() to add MySQL instances.
At least 3 instances are needed for the cluster to be able to withstand up to
one server failure.
这种将返回的集群分配给变量的模式使您能够使用 Cluster 对象的方法对集群执行进一步的操作。返回的 Cluster 对象使用一个新的会话,独立于 MySQL Shell 的全局会话。这确保了如果您更改 MySQL Shell 全局会话,Cluster 对象仍保持其与实例的会话。
为了能够管理集群,您必须确保拥有具有所需权限的合适用户。推荐的方法是创建管理用户。如果您在配置实例时未创建管理用户,请使用该 *Cluster*.setupAdminAccount() 操作。例如,要创建一个名为 的用户, *icadmin*该用户可以管理分配给变量 的 InnoDB Cluster cluster,请发出:
mysql-js> cluster.setupAdminAccount("icadmin")
有关 InnoDB Cluster 管理员帐户的更多信息, 请参阅手动配置InnoDB Cluster 管理员帐户。
该dba.createCluster()操作支持MySQL Shell的interactive选项。开启后 interactive,在以下情况下会出现提示:
- 如果实例属于组复制组,并且
adoptFromGr: true未设置为选项,系统会询问您是否要采用该复制组。 - 如果
force: true未设置为选项,系统会要求您确认多主集群的创建。
当您运行dba.createCluster()以及通过运行 将另一个服务器实例添加到 InnoDB Cluster 时 *Cluster*.addInstance(),以下错误将记录到 MySQL 服务器实例的错误日志中。这些消息是无害的,与 AdminAPI 启动组复制的方式相关:
2020-02-10T10:53:43.727246Z 12 [ERROR] [MY-011685] [Repl] Plugin
group_replication reported: 'The group name option is mandatory'
2020-02-10T10:53:43.727292Z 12 [ERROR] [MY-011660] [Repl] Plugin
group_replication reported: 'Unable to start Group Replication on boot'
笔记
如果您遇到与元数据无法访问相关的错误,您可能配置了环回网络接口。为了正确使用 InnoDB Cluster,请禁用环回接口。
要检查集群是否已创建,请使用集群实例的status()功能。请参阅 使用 检查集群的状态 *Cluster*.status()。
提示
一旦服务器实例属于集群,仅使用 MySQL Shell 和 AdminAPI 来管理它们非常重要。不支持在将实例添加到集群后尝试手动更改实例上的组复制配置。server_uuid同样,不支持在使用 AdminAPI 配置实例后 修改对 InnoDB Cluster 至关重要的服务器变量,例如 。
使用 MySQL Shell 8.0.14 及更高版本创建集群时,您可以设置实例从集群中逐出之前等待的时间(例如,当实例变得无法访问时)。将选项传递expelTimeout给操作,该操作 在种子实例上dba.createCluster()配置 变量。group_replication_member_expel_timeout该 expelTimeout选项可以采用 0 到 3600 范围内的整数值。添加到已配置集群的运行 MySQL 服务器 8.0.13 及更高版本的所有实例 都会自动配置为 与种子实例上配置的值 expelTimeout相同。expelTimeout
有关可以传递给的其他选项的信息 dba.createCluster(),请参阅 第 7.9 节,“修改或解散 InnoDB 集群”。
从 MySQL Shell 8.0.33 开始,可以启用或禁用 group_replication_paxos_single_leader 使用dba.createCluster().
笔记
WRITE_CONSENSUS_SINGLE_LEADER_CAPABLE这只能由 MySQL Server 8.0.31 或更高版本上的 MySQL Shell 设置,因为 MySQL Shell 需要表中 提供的信息 replication_group_communication_information ,该信息是在 MySQL 8.0.31 中引入的。
InnoDB Cluster 复制AllowedHost
当您使用 MySQL Shell 8.0.28 及更高版本创建集群时,如果您有安全要求,即 AdminAPI 自动创建的所有帐户都具有严格的身份验证要求,则可以为 replicationAllowedHost集群配置选项设置一个值。该 replicationAllowedHost选项意味着自动创建的所有帐户只能从允许的主机进行连接,并使用严格的基于子网的过滤。以前, 默认情况下,可以从任何地方访问 InnoDB Cluster 创建的内部用户帐户。
该replicationAllowedHost选项可以采用字符串值。例如,要创建一个名为 的集群 testCluster并将 replicationAllowedHost选项设置为 192.0.2.0/24,请发出:
mysql-js> dba.createCluster('testCluster', {replicationAllowedHost:'192.0.2.0/24'})
配置通信堆栈
从 MySQL Shell 8.0.30 开始,InnoDB Cluster 支持为 MySQL 8.0.27 中的组复制引入的 MySQL 通信堆栈。
该选项communicationStack: XCOM|MYSQL 设置组复制系统变量的值 group_replication_communication_stack。
例如:
mysql-js> dba.createCluster("testCluster", {communicationStack: "xcom"})
通信MYSQL堆栈是为 MySQL 8.0.27 或更高版本创建的所有新集群的默认设置。
有关更多信息,请参见 第 7.5.9 节 “配置组复制通信堆栈”。
7.4.4 添加实例到InnoDB集群
InnoDB Cluster 中至少需要三个实例才能容忍一个实例的故障。添加更多实例可以提高 InnoDB 集群对故障的容忍度。
从版本 8.0.17 开始,组复制实施考虑实例补丁版本的兼容性策略,并且操作会 *Cluster*.addInstance() 检测到这一点,如果不兼容,操作将终止并出现错误。请参阅 检查实例上的 MySQL 版本以及 将不同成员版本合并到一个组中。
如果实例已经包含数据, cluster.checkInstanceState()请先使用该函数验证现有数据不会阻止实例加入集群。请参阅检查实例状态。
使用该 函数将实例添加到集群,其中 是已配置实例的连接信息,请参阅 第 7.4.2 节 “配置 InnoDB 集群使用的生产实例”。例如: *Cluster*.addInstance(*instance*)instance
mysql-js> cluster.addInstance('icadmin@ic-2:3306')
A new instance will be added to the InnoDB cluster. Depending on the amount of
data on the cluster this might take from a few seconds to several hours.
Please provide the password for 'icadmin@ic-2:3306': ********
Adding instance to the cluster ...
Validating instance at ic-2:3306...
This instance reports its own address as ic-2
Instance configuration is suitable.
The instance 'icadmin@ic-2:3306' was successfully added to the cluster.
该addInstance(instance[, options])函数的选项字典提供以下属性:
- label:正在添加的实例的标识符。
- recoveryMethod:状态恢复的首选方法。可以是自动、克隆或增量。默认为自动。
- waitRecovery:整数值,指示命令是否应等待恢复过程完成及其详细级别。
- 密码:实例连接密码。
- memberSslMode:实例上使用的 SSL 模式。
- ipWhitelist:允许连接到实例进行组复制的主机列表。已弃用。
- ipAllowlist:允许连接到实例进行组复制的主机列表。
- localAddress:字符串值,其中包含要使用的组复制本地地址,而不是自动生成的地址。
- groupSeeds:字符串值,其中包含要使用的组复制对等地址的逗号分隔列表,而不是自动生成的地址。已弃用并被忽略。
- Interactive:布尔值,用于禁用/启用命令执行中的向导,即根据设置的值是否提供提示和确认。默认值等于 MySQL Shell 向导模式。
- exitStateAction:指示组复制退出状态操作的字符串值。
- memberWeight:具有百分比权重的整数值,用于故障转移时自动主选举。
- autoRejoinTries:整数值,用于定义实例在被驱逐后尝试重新加入集群的次数。
将新实例添加到集群时,该实例的本地地址会自动添加到 group_replication_group_seeds 所有在线集群实例上的变量中,以便允许它们在需要时使用新实例重新加入组。
笔记
列出的实例 group_replication_group_seeds 按照它们在列表中出现的顺序使用。这可确保首先使用且优先使用用户指定的设置。有关更多信息,请参见第 7.5.2 节“自定义 InnoDB 集群成员服务器”。
如果您使用 MySQL 8.0.17 或更高版本,您可以选择实例如何恢复与集群同步所需的事务。只有当加入的实例恢复了集群之前处理的所有事务时,它才能作为在线实例加入并开始处理事务。有关更多信息,请参阅 第 7.4.6 节 “将 MySQL 克隆与 InnoDB Cluster 结合使用”。
此外,在 8.0.17 及更高版本中,您可以配置 *Cluster*.addInstance() 行为方式,让恢复操作在后台进行或在 MySQL Shell 中监视不同级别的进度。
根据您选择从集群恢复实例的选项,您会在 MySQL Shell 中看到不同的输出。假设您要将实例 ic-2 添加到集群,而 ic-1 是种子或捐赠者。
-
当您使用 MySQL Clone 从集群恢复实例时,输出如下所示:
Validating instance at ic-2:3306...
This instance reports its own address as ic-2:3306
Instance configuration is suitable.
A new instance will be added to the InnoDB cluster. Depending on the amount of
data on the cluster this might take from a few seconds to several hours.
Adding instance to the cluster...
Monitoring recovery process of the new cluster member. Press ^C to stop monitoring
and let it continue in background.
Clone based state recovery is now in progress.
NOTE: A server restart is expected to happen as part of the clone process. If the
server does not support the RESTART command or does not come back after a
while, you may need to manually start it back.
* Waiting for clone to finish...
NOTE: ic-2:3306 is being cloned from ic-1:3306
** Stage DROP DATA: Completed
** Clone Transfer
FILE COPY ############################################################ 100% Completed
PAGE COPY ############################################################ 100% Completed
REDO COPY ############################################################ 100% Completed
NOTE: ic-2:3306 is shutting down...
* Waiting for server restart... ready
* ic-2:3306 has restarted, waiting for clone to finish...
** Stage RESTART: Completed
* Clone process has finished: 2.18 GB transferred in 7 sec (311.26 MB/s)
State recovery already finished for 'ic-2:3306'
The instance 'ic-2:3306' was successfully added to the cluster.
应遵守有关服务器重新启动的警告,您可能必须手动重新启动实例。请参阅 RESTART 语句。
-
当您使用增量恢复从集群中恢复实例时,输出如下所示:
Incremental distributed state recovery is now in progress.
* Waiting for incremental recovery to finish...
NOTE: 'ic-2:3306' is being recovered from 'ic-1:3306'
* Distributed recovery has finished
要取消恢复阶段的监视,请发出 CONTROL+C。这会停止监视,但恢复过程会在后台继续进行。整数 waitRecovery选项可以与操作一起使用 *Cluster*.addInstance() 来控制与恢复阶段有关的命令的行为。接受以下值:
- 0:不等待,让恢复过程在后台完成;
- 1:等待恢复过程完成;
- 2:等待恢复过程完成;并显示详细的静态进度信息;
- 3:等待恢复过程完成;并显示详细的动态进度信息(进度条);
默认情况下,如果运行 MySQL Shell 的标准输出引用终端,则该waitRecovery 选项默认为 3。否则,默认为 2。请参阅 监控恢复操作。
要验证实例是否已添加,请使用集群实例的status()功能。例如,这是添加第二个实例后沙箱集群的状态输出:
mysql-js> cluster.status()
{
"clusterName": "testCluster",
"defaultReplicaSet": {
"name": "default",
"primary": "ic-1:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"ic-1:3306": {
"address": "ic-1:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"ic-2:3306": {
"address": "ic-2:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
},
"groupInformationSourceMember": "mysql://icadmin@ic-1:3306"
}
如何继续取决于实例对于运行 MySQL Shell 的实例是本地实例还是远程实例,以及实例是否支持自动持久配置更改,请参阅第 6.2.4 节 “ 持久设置”。如果实例支持自动保存配置更改,则您无需手动保存设置,可以添加更多实例或继续下一步。如果实例不支持自动持久保存配置更改,您必须在本地配置实例。请参阅配置实例 dba.configureLocalInstance()。这对于确保实例在离开集群时重新加入集群至关重要。
提示
如果实例有 super_read_only=ON,那么您可能需要确认 AdminAPI 可以设置 super_read_only=OFF。更多信息请参见 超级只读模式实例配置。
部署集群后,您可以配置 MySQL Router 以提供高可用性,请参阅 第 6.10 节 “将 MySQL Router 与 AdminAPI、InnoDB Cluster 和 InnoDB ReplicaSet 一起使用”。
检查实例状态
该cluster.checkInstanceState()函数可用于验证实例上的现有数据不会阻止其加入集群。此过程的工作原理是与集群已处理的 GTID 进行比较,验证实例的全局事务标识符 (GTID) 状态。有关 GTID 的更多信息,请参阅 GTID 格式和存储。通过此检查,您可以确定是否可以将已处理事务的实例添加到集群中。
下面演示了在运行的 MySQL Shell 中发出此命令:
mysql-js> cluster.checkInstanceState('icadmin@ic-4:3306')
该函数的输出可以是以下之一:
- OK new:实例没有执行任何GTID事务,因此不能与集群执行的GTID冲突
- OK可恢复:实例执行的GTID与集群种子实例执行的GTID不冲突
- 错误分歧:实例执行的 GTID 与集群种子实例执行的 GTID 不同
- 错误lost_transactions:该实例的执行GTID多于集群种子实例的执行GTID
状态为OK的实例可以添加到集群中,因为该实例上的任何数据都与集群一致。换句话说,被检查的实例没有执行任何与集群执行的 GTID 冲突的事务,并且可以恢复到与其余集群实例相同的状态。
7.4.5 配置InnoDB集群端口
属于集群的实例使用不同的端口进行不同类型的通信。如果您使用 XCOM通信堆栈,除了默认的port3306(用于通过经典 MySQL 协议进行客户端连接)和 mysqlx_port默认的 33060(用于 X 协议客户端连接)之外,还有一个用于内部连接的端口。集群中实例之间的连接,不用于客户端连接。该端口由选项配置localAddress,该选项配置 group_replication_local_address 系统变量,并且该端口必须打开,以便集群中的实例能够相互通信。例如,如果您的防火墙阻止此端口,则实例无法相互通信,并且集群无法运行。同样,如果您的实例使用 SELinux,则需要确保 InnoDB Cluster 使用的所有必需端口均已打开,以便实例可以相互通信。请参阅 设置 MySQL 功能的 TCP 端口上下文和 MySQL Shell 端口。
当您创建集群或向集群添加实例时,默认情况下,localAddress端口的计算方法是将目标实例的 port值乘以 10,然后将结果加 1。例如,当 port目标实例的默认值为3306时,计算出的 端口为33061。您应确保您的集群实例使用的端口号与计算localAddress方式兼容。localAddress例如,如果用于创建集群的服务器实例的port编号大于 6553,则dba.createCluster()操作会失败,因为计算出的值localAddressport端口号超过最大有效端口 65535。要避免这种情况,请在用于 InnoDB Cluster 的实例上 使用较低的 值,或手动分配该localAddress值,例如:
mysql-js> dba.createCluster('testCluster', {'localAddress':'icadmin@ic-1:33061'}
如果您使用MYSQL通信堆栈,则使用与 MySQL 服务器相同的网络地址自动生成 localAddress 值。不需要额外的内部端口/地址。请参见 第 7.5.9 节 “配置组复制通信堆栈”。
localAddress可以手动定义,但使用的端口必须是 MySQL 正在侦听的端口,如 所定义 bind_address。
7.4.6 将 MySQL 克隆与 InnoDB 集群结合使用
- 7.4.6.1 使用 MySQL 克隆的集群
在 MySQL 8.0.17 中,InnoDB Cluster 集成了 MySQL Clone 插件来提供加入实例的自动配置。检索集群的数据以便实例能够与集群同步的过程称为分布式恢复。当实例需要恢复集群的事务时,我们区分 捐赠者(提供数据的集群实例)和接收者,这是从捐赠者接收数据的实例。在之前的版本中,组复制仅提供异步复制来恢复加入实例与集群同步所需的事务,以便其加入集群。对于具有大量先前处理的事务的集群,新实例可能需要很长时间才能恢复所有事务,然后才能加入集群。或者,已清除 GTID 的集群(例如作为定期维护的一部分)可能会丢失恢复新实例所需的一些事务。在这种情况下,唯一的选择是使用 MySQL Enterprise Backup 等工具手动配置实例,如下所示 将 MySQL Enterprise Backup 与组复制结合使用。
MySQL 克隆为实例提供了另一种方法来恢复与集群同步所需的事务。MySQL 克隆不依赖异步复制来恢复事务,而是拍摄捐赠者实例上的数据快照,然后将快照传输到接收者。
警告
在克隆操作期间,接收器中的所有先前数据都会被破坏。然而,所有未存储在表中的 MySQL 设置都会被保留。
一旦克隆操作将快照传输到接收方,如果集群在传输快照时处理了事务,则异步复制用于恢复接收方与集群同步所需的任何数据。这比实例使用异步复制恢复所有事务要高效得多,并且避免了因清除 GTID 引起的任何问题,使您能够快速为 InnoDB Cluster 预置新实例。有关详细信息,请参阅 克隆插件和 用于分布式恢复的克隆
与使用 MySQL 克隆相反,增量恢复是加入集群的实例仅使用异步复制从集群中恢复实例的过程。当InnoDB集群配置为使用MySQL克隆时,加入集群的实例使用MySQL克隆或增量恢复来恢复集群的事务。默认情况下,集群会自动选择最合适的方法,但您可以选择配置此行为,例如强制克隆,这会替换加入实例已处理的任何事务。当您在交互模式下使用 MySQL Shell 时,默认情况下,如果集群不确定是否可以继续恢复,它会提供交互提示。
此外, *Cluster*.status() for Members in RECOVERINGstate 的输出包括恢复进度信息,使您能够轻松监控恢复操作,无论它们是使用 MySQL 克隆还是增量恢复。InnoDB Cluster 在 的输出中提供了有关使用 MySQL Clone 的实例的附加信息 *Cluster*.status()。
7.4.6.1 使用 MySQL 克隆的集群
使用 MySQL 克隆的 InnoDB 集群提供以下附加行为。
dba.createCluster()和 MySQL 克隆
从版本 8.0.17 开始,默认情况下,当在可用 MySQL 克隆插件的实例上创建新集群时,会自动安装该插件并将集群配置为支持克隆。InnoDB Cluster 恢复帐户是使用所需 BACKUP_ADMIN权限创建的。
disableClone将布尔选项 设置true为禁用集群的 MySQL 克隆。在这种情况下,会为此配置添加一个元数据条目,并且如果安装了 MySQL 克隆插件,则会将其卸载。disableClone您可以在发出时 设置该 选项dba.createCluster(),或者在集群运行时随时使用 *Cluster*.setOption().
*Cluster*.addInstance(*instance*) 和 MySQL 克隆
*instance*如果新实例运行 MySQL 8.0.17 或更高版本,并且集群中至少有一个运行 MySQL 8.0.17 或更高版本的捐赠者(包含在列表中 ) ,则可以使用 MySQL 克隆进行加入 group_replication_group_seeds 。使用 MySQL 克隆的集群遵循 第 7.4.4 节“向 InnoDB 集群添加实例”中记录的行为,并添加了如何传输从集群恢复实例所需的数据的可能选择。行为方式 取决于以下因素: *Cluster*.addInstance(*instance*)
-
是否支持MySQL克隆。
-
能否进行增量恢复,取决于二进制日志的可用性。例如,如果捐赠者实例具有所需的所有二进制日志(
GTID_PURGED为空),则可以进行增量恢复。如果没有集群实例拥有所需的所有二进制日志,则增量恢复是不可能的。 -
增量恢复是否合适。尽管增量恢复是可能的,但由于它有可能与实例上已有的数据发生冲突,因此会检查捐赠者和接收者上的 GTID 集以确保增量恢复是适当的。以下是可能的比较结果:
GTID_EXECUTED新:接收方的GTID 集 为空- 相同:接收者的 GTID 集与捐赠者的 GTID 集相同
- 可恢复:接收方的 GTID 集丢失了交易,但可以从捐赠方恢复这些交易
- 不可恢复:捐赠者的 GTID 集丢失了交易,可能已被清除
- Diverged:捐赠者和接收者的GTID集有分歧
当比较结果确定为“相同”或“可恢复”时,认为增量恢复是合适的。当比较结果被确定为Irrecoverable或Diverged时,增量恢复被认为是不合适的。
对于被认为是新的实例,增量恢复不能被认为是合适的,因为无法确定二进制日志是否已被清除,或者即使变量是否
GTID_PURGED被GTID_EXECUTED重置。或者,服务器可能在启用二进制日志和 GTID 之前已经处理了事务。因此在交互模式下,您必须确认要使用增量恢复。 -
选项的状态
gtidSetIsComplete。如果您确定已使用完整的 GTID 集创建了集群,因此可以将具有空 GTID 集的实例添加到其中而无需额外确认,请将集群级别布尔选项设置gtidSetIsComplete为true。警告
gtidSetIsComplete将该选项 设置为true意味着加入服务器将被恢复,无论它们包含什么数据,请谨慎使用。如果您尝试添加已应用事务的实例,您将面临数据损坏的风险。
这些因素的组合会影响您发出命令时实例加入集群的方式 *Cluster*.addInstance()。该recoveryMethod选项默认设置为 auto,这意味着在 MySQL Shell 的交互模式下,集群会选择从集群恢复实例的最佳方式,并且提示会建议您如何继续。换句话说,集群建议根据最佳方法和服务器支持的内容使用 MySQL 克隆或增量恢复。如果您不使用交互模式并且正在编写 MySQL Shell 脚本,则必须设置recoveryMethod 为要使用的恢复类型 – clone或incremental。本节解释了不同的可能场景。
当您在交互模式下使用 MySQL Shell 时,包含添加实例的所有可能选项的主要提示是:
Please select a recovery method [C]lone/[I]ncremental recovery/[A]bort (default Clone):
根据所提到的因素,您可能无法获得所有这些选项。本节后面描述的场景解释了为您提供的选项。该提示提供的选项有:
- 克隆:选择此选项可将捐赠者克隆到您要添加到集群的实例,并删除该实例包含的任何事务。MySQL 克隆插件会自动安装。InnoDB Cluster 恢复帐户是使用所需的信息创建的
BACKUP_ADMIN特权。假设您要添加一个空实例(未处理任何事务)或包含您不想保留的事务,请选择克隆选项。然后,集群使用 MySQL 克隆,用来自捐赠者集群成员的快照完全覆盖加入实例。要默认使用此方法并禁用此提示,请将集群的recoveryMethod选项设置为clone。 - 增量恢复选择此选项可使用增量恢复将集群处理的所有事务恢复到使用异步复制的加入实例。如果您确定集群处理的所有更新都是在启用 GTID 的情况下完成的、没有清除的事务并且新实例包含与集群或其子集相同的 GTID 集,则增量恢复是合适的。要默认使用此方法,请将
recoveryMethod选项设置为incremental。
上述因素的组合会影响提示时可用的选项,如下所示:
笔记
如果 group_replication_clone_threshold 系统变量已在 AdminAPI 外部手动更改,则集群可能决定使用克隆恢复,而不是遵循这些方案。
-
在一个场景中
- 增量恢复是可能的
- 增量恢复不合适
- 支持克隆
您可以在任何选项之间进行选择。建议您使用默认的 MySQL 克隆。
-
在一个场景中
- 增量恢复是可能的
- 增量恢复是适当的
系统不会向您提供提示,并且会使用增量恢复。
-
在一个场景中
- 增量恢复是可能的
- 增量恢复不合适
- 不支持或禁用克隆
您无法使用 MySQL 克隆将实例添加到集群。系统会向您提供提示,建议的选项是继续进行增量恢复。
-
在一个场景中
- 增量恢复是不可能的
- 不支持或禁用克隆
您无法将实例添加到集群,并出现 错误:必须克隆或完全配置目标实例,然后才能将其添加到目标集群。Cluster.addInstance:显示需要实例配置(运行时错误)。这可能是从所有集群实例中清除二进制日志的结果。建议使用 MySQL 克隆,通过升级集群或将选项设置
disableClone为false. -
在一个场景中
- 增量恢复是不可能的
- 支持克隆
您只能使用 MySQL 克隆将实例添加到集群。这可能是集群缺少二进制日志的结果,例如当它们被清除时。
从提示中选择一个选项后,默认情况下会显示实例从集群恢复事务的进度。通过此监控,您可以检查恢复阶段是否正常运行,以及实例加入集群并上线所需的时间。要取消恢复阶段的监视,请发出CONTROL+C。
*Cluster*.checkInstanceState() 和 MySQL 克隆
当 *Cluster*.checkInstanceState() 运行该操作来验证使用 MySQL 克隆的集群的实例时,如果该实例没有二进制日志,例如因为它们已被清除但克隆可用且未禁用 ( 是 ),则该操作会提供一条disableClone警告 false:可以使用克隆。例如:
The cluster transactions cannot be recovered on the instance, however,
Clone is available and can be used when adding it to a cluster.
{
"reason": "all_purged",
"state": "warning"
}
同样,在克隆不可用或已被禁用且二进制日志不可用(例如因为它们已被清除)的实例上,输出包括:
The cluster transactions cannot be recovered on the instance.
{
"reason": "all_purged",
"state": "warning"
}
dba.checkInstanceConfiguration()和 MySQL 克隆
当dba.checkInstanceConfiguration() 对具有可用 MySQL 克隆但已禁用的实例运行该操作时,会显示一条警告。
7.4.7 采用组复制部署
如果您有组复制的现有部署并且想要使用它来创建集群,请将该 adoptFromGR选项传递给该 dba.createCluster()函数。创建的 InnoDB Cluster 匹配复制组是作为单主还是多主运行。
要采用现有的组复制组,请使用 MySQL Shell 连接到组成员。在下面的示例中,采用单基组。我们连接到 gr-member-2,一个辅助实例,同时 gr-member-1充当该组的主要实例。dba.createCluster()使用并传入 选项创建集群 adoptFromGR。例如:
mysql-js> var cluster = dba.createCluster('prodCluster', {adoptFromGR: true});
A new InnoDB cluster will be created on instance 'root@gr-member-2:3306'.
Creating InnoDB cluster 'prodCluster' on 'root@gr-member-2:3306'...
Adding Seed Instance...
Cluster successfully created. Use cluster.addInstance() to add MySQL instances.
At least 3 instances are needed for the cluster to be able to withstand up to
one server failure.
提示
如果实例有 super_read_only=ON,那么您可能需要确认 AdminAPI 可以设置 super_read_only=OFF。更多信息请参见 超级只读模式实例配置。
如果您不指定adoptFromGR: true,并且目标服务器实例属于复制组,MySQL Shell 会提示您确认是否要采用该复制组。从 MySQL Shell 8.0.29 开始,如果指定 adoptFromGR: false,如果发现实例属于复制组,则操作将停止且不提示。
新的集群与组的模式相匹配。如果采用的组在单主模式下运行,则会创建一个单主集群。如果采用的组在多主模式下运行,则会创建多主集群。
笔记
无法在与 相同的命令中定义集群使用的通信堆栈 adoptFromGR,集群最初必须使用采用的组使用的通信堆栈。如有必要,您可以在采用组后使用 更改通信堆栈 rebootClusterFromCompleteOutage。请参见 第 7.5.9 节 “配置组复制通信堆栈”。
7.5 配置InnoDB集群
- 7.5.1 设置InnoDB集群选项
- 7.5.2 定制InnoDB集群成员服务器
- 7.5.3 配置选举过程
- 7.5.4 配置故障切换一致性
- 7.5.5 配置实例自动重新加入
- 7.5.6 配置并行复制应用程序
- 7.5.7 InnoDB集群与自增
- 7.5.8 InnoDB集群和二进制日志清除
- 7.5.9 配置组复制通信堆栈
本节介绍如何在集群创建过程中以及创建之后使用 AdminAPI 对 InnoDB Cluster 进行更详细的配置。您可以使用此信息来修改创建集群时 AdminAPI 默认应用的设置。
7.5.1 设置InnoDB集群选项
您可以在实例在线时检查和修改 InnoDB 集群的设置。要检查集群的当前设置,请使用以下操作:
*Cluster*.options(),其中列出了集群及其实例的配置选项。还可以指定布尔选项all以在输出中包含有关所有组复制系统变量的信息。
您可以在集群级别或实例级别配置 InnoDB Cluster 的选项,同时实例保持在线状态。这避免了需要删除、重新配置然后再次添加实例来更改 InnoDB Cluster 选项。使用以下操作:
*Cluster*.setOption(*option*, *value*)全局更改所有集群实例的设置或集群全局设置,例如clusterName.*Cluster*.setInstanceOption(instance, *option*, *value*)更改各个集群实例的设置
将 InnoDB Cluster 选项与列出的操作一起使用的方式取决于是否可以将该选项更改为在所有实例上都相同。这些选项在集群(所有实例)和每个实例级别都是可更改的:
-
autoRejoinTries:整数值,定义实例在被驱逐后尝试重新加入集群的次数。请参见 第 7.5.5 节 “配置实例的自动重新加入”。 -
exitStateAction:指示组复制退出状态操作的字符串值。请参见 第 7.5.5 节 “配置实例的自动重新加入”。 -
memberWeight:具有百分比权重的整数值,用于故障转移时自动主选举。请参见 第 7.5.3 节“配置选举过程”。 -
ipAllowList:以逗号分隔的 IP 地址列表或子网 CIDR 表示法。例如:192.168.1.0/24,10.0.0.1. 默认情况下,该值设置为AUTOMATIC,允许将来自实例专用网络的地址自动设置为白名单。笔记
communicationStack仅当设置为 时才能设置此选项XCOM。 -
tag:*option*:与集群关联的内置标签和用户定义标签。请参见第 6.9 节“标记元数据”。
这些选项只能在集群级别更改:
clusterName:定义集群名称的字符串值disableClone:用于禁用集群上克隆使用的布尔值。请参阅dba.createCluster()和 MySQL 克隆。replicationAllowedHost:字符串值,用于定义严格的基于子网的过滤,以便内部管理的复制帐户只能从允许的主机进行连接。请参阅 InnoDB 集群replicationAllowedHost。expelTimeout:整数值,用于定义集群成员在将其从集群中逐出之前应等待无响应成员的时间段(以秒为单位)。请参见第 7.4.3 节“创建 InnoDB 集群”。failoverConsistency:表示集群提供的一致性保证的字符串值。请参见 第 7.5.5 节 “配置实例的自动重新加入”。transactionSizeLimit:设置组复制系统变量的正整数值group_replication_transaction_size_limit。这设置集群接受的最大事务大小(以字节为单位)。较大的事务将回滚并且不会广播到集群。添加到集群的所有成员都使用相同的值。
此选项仅可在每个实例级别更改:
label:实例的字符串标识符
7.5.2 定制InnoDB集群成员服务器
当您创建集群并向其中添加实例时,组名称和本地地址等值将由 AdminAPI 自动配置。建议大多数部署使用默认值,但高级用户可以通过将以下选项传递给 dba.createCluster()和 *Cluster*.addInstance() 命令来覆盖默认值:
- 将选项传递
groupName给dba.createCluster()命令以自定义 InnoDB Cluster 创建的复制组的名称。这设置了group_replication_group_name系统变量。该名称必须是有效的 UUID。 - 将
localAddress选项传递给dba.createCluster()和cluster.addInstance()命令以自定义实例为来自其他实例的连接提供的地址。以格式指定地址 。这会 在实例上设置系统变量。该地址必须可供集群中的所有实例访问,并且必须仅为内部集群通信保留。换句话说,不要使用该地址与实例进行通信。*host*:*port*group_replication_local_address
有关详细信息,请参阅这些 AdminAPI 选项配置的系统变量的文档。
7.5.3 配置选举过程
您可以选择配置单主集群如何选择新的主集群,例如选择一个实例作为故障转移到的新主集群。创建集群时使用该memberWeight 选项并将其传递给dba.createCluster() 和方法。Cluster.addInstance()该memberWeight 选项接受 0 到 100 之间的整数值,这是故障转移时自动主选举的百分比权重。当实例的百分比数设置较高时 memberWeight,它更有可能被选为单主集群中的主实例。当进行初选时,如果多个实例具有相同的 memberWeight值,然后根据服务器 UUID 按字典顺序(最低)并选择第一个实例对实例进行优先级排序。
设置 的值会 在实例上memberWeight配置 系统变量。group_replication_member_weight组复制将值范围限制为 0 到 100,如果提供更高或更低的值,则会自动调整它。如果未提供值,组复制将使用默认值 50。有关详细信息, 请参阅 单主模式。
例如,要配置一个集群,其中是在当前主实例意外离开集群时ic-3 故障转移到的首选实例 ,请使用以下命令: ic-1``memberWeight
dba.createCluster('cluster1', {memberWeight:35})
var mycluster = dba.getCluster()
mycluster.addInstance('icadmin@ic2', {memberWeight:25})
mycluster.addInstance('icadmin@ic3', {memberWeight:50})
7.5.4 配置故障切换一致性
如果主故障转移发生在单主模式下, 组复制提供了指定故障转移保证(最终或“读取您的写入” ) 的能力(请参阅配置事务一致性保证)。您可以在创建时配置 InnoDB Cluster 的故障转移保证,方法是将选项consistency(在版本 8.0.16 之前是该选项 failoverConsistency,现已弃用)传递给操作dba.createCluster() ,该操作配置 group_replication_consistency 种子实例上的系统变量。此选项定义在单主组中选举新主节点时使用的新防护机制的行为。防护会限制连接从新主数据库进行写入和读取,直到它应用了来自旧主数据库的任何挂起的积压更改(有时称为“读取您的写入”)。当防护机制到位时,在应用任何积压工作时,应用程序实际上不会看到时间在短时间内倒退。这可确保应用程序不会从新选出的主节点读取过时的信息。
仅当目标 MySQL 服务器版本为 8.0.14 或更高版本时才支持该consistency选项,并且添加到已配置该选项的集群的实例 consistency会自动配置为在 group_replication_consistency 支持该选项的所有集群成员上具有相同的实例。变量默认值由组复制控制,将选项 EVENTUAL更改 为启用防护机制。或者使用 for 和for 。 consistency``BEFORE_ON_PRIMARY_FAILOVER``consistency=0``EVENTUAL``consistency=1``BEFORE_ON_PRIMARY_FAILOVER
笔记
在多主 InnoDB 集群上使用该consistency选项没有任何效果,但允许,因为稍后可以通过该 *Cluster*.switchToSinglePrimaryMode() 操作将集群更改为单主模式。
7.5.5 配置实例自动重新加入
MySQL 8.0.16及以上版本的实例支持组复制自动重新加入功能,您可以配置实例被驱逐后自动重新加入集群。有关背景信息,请参阅 对故障检测和网络分区的响应 。AdminAPI 提供了 autoRejoinTries配置实例在被驱逐后重新加入集群的尝试次数的选项。默认情况下,实例不会自动重新加入集群。autoRejoinTries您可以使用以下命令在集群级别或单个实例 配置该 选项:
dba.createCluster()Cluster.addInstance()Cluster.setOption()Cluster.setInstanceOption()
该autoRejoinTries选项接受 0 到 2016 之间的正整数值,默认值为 3。使用自动重新加入功能时,您的集群对故障的容忍度更高,尤其是临时故障,例如不可靠的网络。但如果仲裁已丢失,您不应期望成员自动重新加入集群,因为需要多数才能重新加入实例。
运行 MySQL 版本 8.0.12 及更高版本的实例具有该 group_replication_exit_state_action 变量,您可以使用 AdminAPI exitStateAction选项配置该变量。这控制实例在意外离开集群时执行的操作。默认情况下,该exitStateAction选项 READ_ONLY,意味着意外离开集群的实例将变为只读。如果 exitStateAction设置为 OFFLINE_MODE(从 MySQL 8.0.18 开始),离开集群的实例会意外变为只读,并进入离线模式,在该模式下,它们会断开现有客户端的连接,并且不接受新连接(具有管理员权限的客户端除外)。如果 exitStateAction设置为 ABORT_SERVER然后,如果意外离开集群,实例将关闭 MySQL,并且必须重新启动才能重新加入集群。请注意,当您使用自动重新加入功能时,该选项配置的操作exitStateAction 仅在所有重新加入集群的尝试都失败的情况下才会发生。
您有可能连接到一个实例并尝试使用 AdminAPI 配置它,但此时该实例可能会重新加入集群。每当您使用以下任何操作时都可能发生这种情况:
Cluster.status()dba.getCluster()Cluster.rejoinInstance()Cluster.addInstance()Cluster.removeInstance()Cluster.rescan()Cluster.checkInstanceState()
当实例自动重新加入集群时,这些操作可能会提供额外的信息。此外,当您使用 时 *Cluster*.removeInstance(),如果目标实例自动重新加入集群,则操作将中止,除非您传入 force:true。
7.5.6 配置并行复制应用程序
从版本 8.0.23 开始,实例支持并启用并行复制应用程序线程,有时称为多线程副本。并行使用多个副本应用程序线程可提高复制应用程序和增量恢复的吞吐量。
这意味着在运行 8.0.23 及更高版本的实例上,必须配置以下系统变量:
binlog_transaction_dependency_tracking=WRITESETslave_preserve_commit_order=ONslave_parallel_type=LOGICAL_CLOCKtransaction_write_set_extraction=XXHASH64
默认情况下,应用程序线程数(由 slave_parallel_workers系统变量配置)设置为 4。
当您升级运行早于 8.0.23 版本的 MySQL 服务器和 MySQL Shell 的集群时,实例不会配置为使用并行复制应用程序。如果未启用并行应用程序,操作的输出 *Cluster*.status() 将在字段中显示一条消息 instanceErrors,例如:
...
"instanceErrors": [
"NOTE: The required parallel-appliers settings are not enabled on
the instance. Use dba.configureInstance() to fix it."
...
在这种情况下,您应该重新配置实例,以便它们使用并行复制应用程序。对于属于 InnoDB Cluster 的每个实例,通过发出 来更新配置dba.configureInstance(instance)。请注意,通常dba.configureInstance()在将实例添加到集群之前使用,但在这种特殊情况下,无需删除实例,并且配置更改是在实例在线时进行的。
有关并行复制应用程序的信息显示在 *Cluster*.status(extended=1) 操作的输出中。例如,如果启用并行复制应用程序,则topology实例的部分输出将显示 下的线程数 applierWorkerThreads。为并行复制应用程序配置的系统变量显示在操作的输出中 *Cluster*.options() 。
您可以使用 选项配置实例用于并行复制应用程序的线程数 applierWorkerThreads,默认为 4 个线程。该选项接受 0 到 1024 范围内的整数,并且只能与 dba.configureInstance()and dba.configureReplicaSetInstance()运算一起使用。例如,要使用 8 个线程,请发出:
mysql-js> dba.configureInstance(instance, {applierWorkerThreads: 8, restart: true})
笔记
并行复制应用程序使用的线程数的更改仅在实例重新启动并重新加入集群后发生。
要禁用并行复制应用程序,请将该 applierWorkerThreads选项设置为 0。
7.5.7 InnoDB集群与自增
当您使用实例作为 InnoDB 集群的一部分时,配置auto_increment_increment 和auto_increment_offset 变量以避免最大大小为 9(组复制组支持的最大大小)的多主集群发生自动增量冲突的可能性。用于配置这些变量的逻辑可以概括为:
- 如果组以单主模式运行,则设置
auto_increment_increment为 1 和auto_increment_offset2。 - 如果组在多主模式下运行,则当集群有 7 个或更少实例时,设置
auto_increment_increment为 7 和auto_increment_offset1 +server_id% 7。如果多主集群有 8 个或更多实例,则设置auto_increment_increment为实例数和auto_increment_offset1 +server_id% 实例数。
7.5.8 InnoDB集群和二进制日志清除
在 MySQL 8 中,二进制日志会自动清除(如定义binlog_expire_logs_seconds)。这意味着运行时间较长的集群 binlog_expire_logs_seconds 最终可能不包含具有完整二进制日志的实例,该二进制日志包含实例应用的所有事务。这可能会导致需要自动配置实例,例如使用 MySQL Enterprise Backup,然后才能加入集群。运行 8.0.17 及更高版本的实例支持 MySQL Clone 插件,该插件通过提供不依赖增量恢复的自动配置解决方案解决了此问题,请参阅第 7.4.6 节 “将 MySQL Clone 与 InnoDB Cluster 结合使用”。运行 8.0.17 之前版本的实例仅支持增量恢复,结果是,根据实例运行的 MySQL 版本,可能必须自动配置实例。否则,诸如此类的依赖于分布式恢复的操作 *Cluster*.addInstance() 可能会失败。
在运行早期版本 MySQL 的实例上,以下规则用于二进制日志清除:
- 运行 8.0.1 之前版本的实例没有自动二进制日志清除功能,因为 的默认值为
expire_logs_days0。 - 运行 8.0.1 之后但早于 8.0.4 的版本的实例会在 30 天后清除二进制日志,因为 的默认值为
expire_logs_days30。 - 运行 8.0.10 之后版本的实例会在 30 天后清除二进制日志,因为 的默认值为
binlog_expire_logs_seconds2592000,而 的默认值为expire_logs_days0。
因此,根据集群运行的时间,二进制日志可能已被清除,并且您可能必须手动配置实例。同样,如果您手动清除二进制日志,您可能会遇到相同的情况。因此,强烈建议您升级到 MySQL 8.0.17 之后的版本,以充分利用 MySQL Clone 提供的自动配置功能进行分布式恢复,并在为 InnoDB Cluster 配置实例时最大程度地减少停机时间。
7.5.9 配置组复制通信堆栈
从 MySQL Shell 8.0.30 开始,InnoDB Cluster 和 ClusterSet 支持 MySQL 8.0.27 中为组复制引入的 MySQL 通信堆栈。
新选项communicationStack: XCOM|MYSQL设置 Group Replication 系统变量的值 group_replication_communication_stack。
笔记
无法将该 communicationStack选项与 一起 使用adoptfromGR。
通信堆栈类型
支持以下通信堆栈:
-
MYSQL:(MySQL Server 8.0.27 或更高版本的默认值)
- 通过使用 MySQL Server 的连接安全性代替组复制实现来简化 InnoDB 集群的创建。
- 内部组复制通信不再需要额外的网络地址或端口。
- 使用 MYSQL 协议意味着可以使用标准的用户身份验证方法代替允许列表来授予或撤销对组的访问权限。
- 支持组复制的网络命名空间。
Oracle 建议使用
MYSQL通信堆栈而不是XCOM. -
XCOM:(MySQL Server 8.0.26 或更早版本的默认设置)。您可以将 XCOM 通信堆栈与 MySQL 8.0.27 或更高版本一起使用,但必须在创建或重新启动命令中显式定义。
XCOM 使用安全协议的组复制实现(包括 TLS/SSL 以及使用传入组通信系统 (GCS) 连接的允许列表)来保护成员之间的组通信连接和分布式恢复连接。
选择通信堆栈
通信堆栈选择由和 命令communicationStack中的选项 设置 。 dba.createCluster()``.createReplicaCluster()
例如:
js> dba.createCluster("testCluster", {communicationStack: "mysql"})
js> clusterset.createReplicaCluster("hostname:3306", "replica", {communicationStack: "mysql"})
每个命令都会检查 MySQL 服务器以确保它可以使用该 MYSQL协议。如果不支持 MYSQL,则会显示错误并且命令失败。
、和 命令还会检查目标实例的通信堆栈支持并相应地设置所需的配置选项 addInstance。 rejoinInstance``rescan
-
ipAllowList。XCOM:默认自动设置。MYSQL: 未设置。ipAllowList通信堆栈不允许MYSQL。
-
localAddress-
XCOM:(高级选项,不推荐)自动生成。需要额外的网络地址或端口。 -
MYSQL:自动更新为使用 MySQL 服务器报告的值。localAddress可以手动定义,但端口必须是 MySQL 正在侦听的端口,如 所定义bind_address。
-
-
groupSeedsXCOM: 自动生成。需要额外的网络地址或端口。MYSQL: 自动更新为使用bind_address每个 MySQL 实例使用的值。
-
更新 SSL 设置。两种通信协议使用相同的 SSL 设置。
memberSslMode如果设置为 VERIFY_CA 或 VERIFY_IDENTITY,则从 MySQL 服务器复制设置。memberSslMode如果设置为 REQUIRED, 则不会进行任何更改。笔记
group_replication_recovery_use_ssl``memberSslMode如果设置为 DISABLED 以外的任何值, 则始终启用。
交换通信堆栈
可以在完全中断操作重新启动期间切换通信堆栈。
例如:
js> dba.rebootClusterFromCompleteOutage("testcluster", {switchCommunicationStack: "mysql"})
从MYSQL协议切换到 XCOM需要额外的网络地址,并且localAddress可能还需要 ipAllowList值。
如果从 XCOM 切换到 MYSQL 堆栈,则会进行以下更改:
-
ipAllowList未设置。 -
localAddress更新为使用 MySQL 服务器报告的值。 -
groupSeeds更新为使用bind_address每个 MySQL 实例使用的值。 -
更新 SSL 设置。
memberSslMode如果设置为 VERIFY_CA 或 VERIFY_IDENTITY,则从 MySQL 服务器复制设置。memberSslMode如果设置为 REQUIRED, 则不会进行任何更改 。笔记
group_replication_recovery_use_ssl``memberSslMode如果设置为 DISABLED 以外的任何值, 则始终启用。
7.6 保护InnoDB集群
服务器实例可以配置为使用安全连接。有关使用 MySQL 安全连接的一般信息,请参阅 使用加密连接。本节介绍如何配置集群以使用加密连接。另一种安全可能性是配置哪些服务器可以访问集群,请参阅创建服务器允许列表。
重要的
如果您使用XCOM通信堆栈,一旦将集群配置为使用加密连接,您必须将服务器添加到 ipAllowlist. 例如,使用商业版MySQL时,默认启用SSL,您需要ipAllowlist为所有实例配置该选项。请参阅创建服务器白名单。
当用于dba.createCluster()设置集群时,如果服务器实例提供加密,那么它会在种子实例上自动启用。将选项传递 memberSslMode给 dba.createCluster()方法以指定不同的 SSL 模式。集群的SSL模式只能在创建时设置。该memberSslMode选项是一个配置要使用的 SSL 模式的字符串,默认为AUTO。支持以下模式:
DISABLED:确保集群中的种子实例禁用 SSL 加密。AUTO:如果服务器实例支持,则自动启用 SSL 加密;如果服务器实例不支持,则禁用加密。REQUIRED:为集群中的种子实例启用SSL加密。如果无法启用,则会引发错误。VERIFY_CA:与 类似REQUIRED,但还根据配置的 CA 证书验证服务器证书颁发机构 (CA) 证书。如果未找到有效的匹配 CA 证书,连接尝试将失败。VERIFY_IDENTITY:与 类似VERIFY_CA,但还通过根据服务器发送给客户端的证书中的身份检查客户端用于连接到服务器的主机名来执行主机名身份验证。
例如,要将集群设置为使用 REQUIRED,请发出:
mysql-js> var myCluster = dba.createCluster({memberSslMode: 'REQUIRED'})
如果您选择使用VERIFY_CA或 模式,则必须在每个集群实例上使用和/或 选项VERIFY_IDENTITY手动提供 CA 证书 。有关这些模式的更多信息,请参阅 。 ssl_cassl_capath--ssl-mode=*mode*
当您使用 *Cluster*.addInstance() 和 *Cluster*.rejoinInstance() 操作时,会根据集群使用的设置启用或禁用实例上的 SSL 加密。使用该 memberSslMode选项与这些操作之一可将实例设置为使用不同的加密模式。
当与采用现有组复制组的dba.createCluster()选项一起 使用时adoptFromGR,所采用的集群上的 SSL 设置不会更改:
memberSslMode不能与 一起使用adoptFromGR。- 如果采用的集群的 SSL 设置与 MySQL Shell 支持的 SSL 设置不同,即用于组复制恢复和组通信的 SSL,则这两个设置都不会被修改。这意味着您无法向集群添加新实例,除非您手动更改所采用集群的设置。
MySQL Shell 始终为集群启用或禁用 SSL 以进行组复制恢复和组通信,请参阅 使用安全套接字层 (SSL) 保护组通信连接。将新实例添加到集群时,如果种子实例的这些设置不同(例如,dba.createCluster()使用 using 的结果),则会执行验证并发出错误。adoptFromGR必须为集群中的所有实例启用或禁用 SSL 加密。执行验证以确保在向集群添加新实例时此不变量成立。
该dba.deploySandboxInstance()命令尝试部署默认支持 SSL 加密的沙盒实例。如果不可能,则部署服务器实例时不支持 SSL。请参见 第 6.8.1 节 “部署沙箱实例”。
确保集群成员之间的通信安全
从 MySQL Shell 8.0.33 开始,可以将集群和副本集群配置为使用 SSL 加密复制通道,并使副本能够验证主机身份并使用 SSL 证书进行身份验证。
创建集群时, dba.createCluster()您可以使用 选项定义用于内部复制帐户的身份验证类型memberAuthType。该选项采用以下值之一:
PASSWORD:帐户仅使用密码进行身份验证。CERT_ISSUER:帐户使用客户端证书进行身份验证,该证书必须与预期的颁发者匹配。该值相当于VERIFY_CA.CERT_SUBJECT:帐户使用客户端证书进行身份验证,该证书必须与预期的颁发者和主题相匹配。该值相当于VERIFY_IDENTITY.CERT_ISSUER_PASSWORD``PASSWORD:帐户使用和 值的组合进行身份验证CERT_ISSUER。CERT_SUBJECT_PASSWORD``PASSWORD:帐户使用和 值的组合进行身份验证CERT_SUBJECT。
重要的
ClusterSet 继承memberAuthType 主集群上的定义。ClusterSet 中的所有副本集群也将使用memberAuthType 主集群上定义的集群。
SSL 证书使用以下选项定义:
CERT_ISSUER``memberAuthType:如果包含CERT_ISSUER或 , 则定义拓扑中所有复制帐户所需的证书颁发者CERT_SUBJECT。CERT_SUBJECT:定义实例的证书主体。如果memberAuthType包含 ,则为必填项CERT_SUBJECT。
笔记
不能adoptFromGR=true 与任何memberAuthTypeexcept 一起使用password。
以下示例创建一个集群, cluster1它将客户端 SSL 连接和组复制打开的从一台服务器到另一台服务器的连接设置为 VERIFY_IDENTITY,并将内部复制帐户的身份验证设置为需要客户端证书:
cluster = dba.createCluster("cluster1", { "memberSslMode": "VERIFY_IDENTITY", "memberAuthType":"CERT_SUBJECT",
"certIssuer":"/CN=MyCertAuthority", "certSubject": "/CN=mysql-1.local"});
以下示例展示了如何使用以下命令将实例添加到集群"memberAuthType":"CERT_SUBJECT":
cluster.addInstance("mysql-2.local", {"certSubject": "/CN=mysql-2.local"});
有关复制和加密连接的更多信息,请参阅设置复制以使用加密连接。
创建服务器白名单
笔记
这仅适用于XCOM通信堆栈。
createCluster()、 addInstance()和 rejoinInstance()方法使您可以选择指定已批准服务器的列表(称为允许列表)。通过以这种方式显式指定白名单,您可以提高集群的安全性,因为只有白名单中的服务器才能连接到集群。
您还可以在正在运行的集群上定义allowList,用于 *Cluster*.setOption() 为集群的所有成员指定allowList,并 *Cluster*.setInstanceOption() 为单个成员指定allowList。请参见 第 7.5.1 节“InnoDB Cluster 的设置选项”。
使用该ipAllowlist选项(以前 ,现在已弃用) 在实例上ipWhitelist配置 系统变量。group_replication_ip_allowlist默认情况下,如果未明确指定,白名单将自动设置为服务器具有网络接口的专用网络地址。要配置白名单,请在使用该方法时通过选项指定要添加的服务器 ipAllowlist。IP 地址必须以 IPv4 格式指定。将服务器作为逗号分隔列表传递,并用引号引起来。例如:
mysql-js> cluster.addInstance("icadmin@ic-3:3306", {ipAllowlist: "203.0.113.0/24, 198.51.100.110"})
这将实例配置为仅接受来自地址203.0.113.0/24和 的 服务器的连接198.51.100.110。允许列表还可以包括主机名,仅当另一台服务器发出连接请求时才会解析这些主机名。
警告
主机名本质上不如白名单中的 IP 地址安全。MySQL 执行 FCrDNS 验证,这提供了良好的保护级别,但可能会受到某些类型的攻击的影响。仅当绝对必要时才在白名单中指定主机名,并确保用于名称解析的所有组件(例如 DNS 服务器)均在您的控制之下。您还可以使用主机文件在本地实现名称解析,以避免使用外部组件。
7.8 恢复和重启InnoDB集群
- 7.8.1 实例重新加入集群
- 7.8.2 从仲裁丢失中恢复集群
- 7.8.3 从严重中断中重新启动集群
- 7.8.4 重新扫描集群
- 7.8.5 隔离集群
本节介绍如何将服务器实例重新加入 InnoDB 集群、从仲裁丢失中恢复 InnoDB 集群或在中断后重新启动它,以及在更改后重新扫描 InnoDB 集群。
7.8.1 实例重新加入集群
如果实例离开集群,例如因为失去连接,并且由于某种原因无法自动重新加入集群,则可能需要在稍后阶段将其重新加入集群。将实例重新加入集群问题 。 *Cluster*.rejoinInstance(*instance*)
提示
如果实例有 super_read_only=ON,那么您可能需要确认 AdminAPI 可以设置 super_read_only=OFF。更多信息请参见 超级只读模式实例配置。
如果实例尚未保留其配置(请参阅第 6.2.4 节 “保留设置”),则重新启动后,实例不会自动重新加入集群。解决方案是发出命令 cluster.rejoinInstance(),以便将实例再次添加到集群中,并确保更改得到持久化。一旦 InnoDB 集群配置保存到实例的选项文件中,它就会自动重新加入集群。
如果您要重新加入以某种方式发生更改的实例,那么您可能必须修改该实例才能使重新加入过程正常工作。例如,当您恢复 MySQL Enterprise Backup 备份时,会发生server_uuid 更改。尝试重新加入此类实例会失败,因为 InnoDB Cluster 实例是由该 server_uuid变量标识的。在这种情况下,必须从 InnoDB Cluster 元数据中删除有关实例旧实例的信息 server_uuid,然后 *Cluster*.rescan() 必须执行 a 以使用新实例将实例添加到元数据中server_uuid。例如:
cluster.removeInstance("root@instanceWithOldUUID:3306", {force: true})
cluster.rescan()
在这种情况下,您必须将该force选项传递给该 *Cluster*.removeInstance() 方法,因为从集群的角度来看该实例是无法访问的,并且我们无论如何都希望将其从 InnoDB Cluster 元数据中删除。
rejoinInstance()还检查实例使用的通信堆栈并确保它受到集群的支持。如果集群支持通信堆栈,rejoinInstance()则将实例添加到集群中。
7.8.2 从仲裁丢失中恢复集群
如果一个实例(或多个实例)发生故障,则集群可能会失去其法定人数,即在新主实例中投票的能力。当足够多的实例发生故障以致组成集群的大多数实例不再对组复制操作进行投票时,就会发生这种情况。请参阅 容错。当集群失去仲裁时,您无法再处理集群的写入事务,也无法更改集群的拓扑,例如通过添加、重新加入或删除实例。但是,如果您有一个包含 InnoDB 集群元数据的在线实例,则可以通过仲裁恢复集群。这假设您可以连接到包含 InnoDB 集群元数据的实例,并且该实例可以联系您要用于恢复集群的其他实例。
重要的
此操作具有潜在危险,因为如果使用不当,可能会造成脑裂情况,应将其视为最后的手段。绝对确保该组中没有任何分区仍在网络中的某个位置运行,但无法从您的位置进行访问。
连接到包含集群元数据的实例,然后使用该 操作,该操作根据 上的元数据恢复集群 ,然后从给定实例定义的角度来看的 所有实例都将添加到恢复的集群中。*Cluster*.forceQuorumUsingPartitionOf(*instance*)instanceONLINE
mysql-js> cluster.forceQuorumUsingPartitionOf("icadmin@ic-1:3306")
Restoring replicaset 'default' from loss of quorum, by using the partition composed of [icadmin@ic-1:3306]
Please provide the password for 'icadmin@ic-1:3306': ******
Restoring the InnoDB cluster ...
The InnoDB cluster was successfully restored using the partition from the instance 'icadmin@ic-1:3306'.
WARNING: To avoid a split-brain scenario, ensure that all other members of the replicaset
are removed or joined back to the group that was restored.
如果实例未自动添加到集群,例如其设置未保留,请 *Cluster*.rejoinInstance() 手动将实例添加回集群。
恢复的集群可能不会、也不必包含组成集群的所有原始实例。例如,如果原始集群由以下五个实例组成:
ic-1ic-2ic-3ic-4ic-5
集群经历裂脑场景, 、 ic-1、ic-2和 ic-3形成一个分区,而 ic-4和ic-5形成另一个分区。如果您连接到ic-1并发出 *Cluster*.forceQuorumUsingPartitionOf('icadmin@ic-1:3306') 恢复集群的命令,生成的集群将包含以下三个实例:
ic-1ic-2ic-3
因为ic-1看到了并且ic-2没有 看到并且。 ic-3``ONLINE``ic-4``ic-5
7.8.3 从严重中断中重新启动集群
如果您的集群遇到完全中断,您可以使用 重新配置它 dba.rebootClusterFromCompleteOutage()。此操作使您能够连接到集群的 MySQL 实例之一并使用其元数据来恢复集群。
完全中断意味着所有成员实例上的组复制已停止。
笔记
运行之前确保所有集群成员都已启动 dba.rebootClusterFromCompleteOutage()。如果任何集群成员无法访问,该命令将失败。
如果集群已 INVALIDATED 并且是 ClusterSet 的成员,则忽略此检查。
连接到最新的实例并运行以下命令:
JS> var cluster = dba.rebootClusterFromCompleteOutage()
如果所有成员都设置了相同的 GTID,则您当前连接的成员将成为主要成员。请参阅 使用rebootClusterFromCompleteOutage 选择主节点。
该dba.rebootClusterFromCompleteOutage() 操作遵循以下步骤以确保正确地重新配置集群:
-
集群元数据和集群拓扑是从当前实例中检索的。
-
如果集群成员处于 RECOVERING 或 ERROR 状态,并且所有其他成员处于 OFFLINE 或 ERROR 状态,
dba.rebootClusterFromCompleteOutage()则尝试停止该成员上的组复制。如果组复制无法停止,该命令将停止并显示错误。 -
检查在 MySQL Shell 当前连接到的实例上找到的 InnoDB Cluster 元数据,以查看它是否包含 GTID 超集。如果当前连接的实例不包含 GTID 超集,则操作将使用该信息中止。
请参阅GTID 超集。
-
如果实例包含 GTID 超集,则根据该实例中存储的元数据恢复集群。
-
MySQL Shell 检查集群的哪些实例当前可访问,如果任何成员当前不可访问,则失败。
笔记
使用该选项可以绕过此检查
force。这将使用剩余的可联系成员重新启动集群。请参阅强制选项。
-
同样,MySQL Shell 会检测当前无法访问的实例。
dba.rebootClusterFromCompleteOutage()如果以前的成员当前无法访问,则 无法作为该命令的一部分向集群添加或删除以前的成员 。 -
如果在集群的主实例上启用,则在单主模式下
super_read_only将被禁用。
GTID 超集
要重新启动集群,您必须连接到具有 GTID 超集的成员,这意味着在中断之前应用了最多事务的实例。
要确定哪个成员具有 GTID 超集,请执行以下操作之一:
-
连接到实例并使用
dba.rebootClusterFromCompleteOutage()运行dryRun: true。生成的报告返回类似于以下内容的信息:Switching over to instance '127.0.0.1:4001' to be used as seed.
这表示具有 GTID 超集的成员。
针对具有较低 GTID 集的成员运行
dba.rebootClusterFromCompleteOutage()会导致错误。 -
依次连接到每个实例并在
SQL模式下运行以下命令:SHOW VARIABLES LIKE 'gtid_executed';
应用了最大GTID事务集的 实例 包含GTID超集。
笔记
dba.rebootClusterFromCompleteOutage() 通过使用该选项 运行,可以覆盖此行为,并使用具有较低 GTID 集的实例 force。
这使得所选成员成为主要成员,并丢弃未包含在所选成员的 GTID 集中的任何事务。
如果此过程失败,并且集群元数据已严重损坏,您可能需要删除元数据并从头开始重新创建集群。您可以使用删除集群元数据 dba.dropMetadataSchema()。
警告
dba.dropMetadataSchema()仅当无法恢复集群时,才应将该方法用作最后的手段 。它无法撤消。
如果您在集群中使用 MySQL Router,则当您删除元数据时,所有当前连接都将被删除,并且新连接将被禁止。这会导致完全中断。
选项
dba.rebootClusterFromCompleteOutage()有以下选项:
force: true | false (default):如果为 true,则即使无法访问集群的某些成员,或者选择的主实例具有发散或较低的 GTID_SET,也必须执行该操作。请参阅 强制选项dryRun: true | false (default):执行命令的所有验证和步骤,但不进行任何更改。完成后会显示一份报告。请参阅 测试rebootClusterFromCompleteOutage。primary:实例定义,表示必须选为主实例的实例。请参阅 使用rebootClusterFromCompleteOutage 选择主节点。switchCommunicationStack: mysql | xcom:集群重启后使用的组复制协议栈。请参见 第 7.5.9 节 “配置组复制通信堆栈”。ipAllowList:使用协议栈时允许连接到实例进行组复制流量的主机列表XCOM。localAddress:使用协议栈时使用组复制本地地址的字符串值,而不是自动生成的地址XCOM。
强制选项
该force选项使您能够忽略集群成员的可用性或所选成员中 GTID 集的差异并重新启动集群。
例如,重新启动集群 myCluster:
JS> var cluster = dba.rebootClusterFromCompleteOutage("myCluster",{force: true})
force在以下情况下不允许使用 该选项:
- 如果 Cluster 属于 ClusterSet 并且处于 INVALIDATED 状态或者主 Cluster 不处于全局状态 OK,
- 该 Cluster 属于 ClusterSet,是主 Cluster,并且已无效。
无法使用 来添加或重新加入实例 rebootClusterFromCompleteOutage。如果您曾经force忽略无法访问的成员并重新启动集群,则必须使用 *cluster*.rejoinInstance() 将无法访问的成员添加到集群中。
使用rebootClusterFromCompleteOutage 选择主节点
您可以通过以下方式之一定义集群主节点:
-
定义命令
primary中的选项dba.rebootClusterFromCompleteOutage()。例如,重新启动集群
myCluster并将在本地计算机上端口 4001 上运行的成员设置为主要成员:var cluster = dba.rebootClusterFromCompleteOutage("myCluster",{primary: "127.0.0.1:4001"})
-
通过将该
primary选项force与 GTID 设置低于其他成员的集群成员上的选项结合使用。
测试 restartClusterFromCompleteOutage
您可以使用该选项来测试更改 dryRun。此选项验证命令及其选项并生成结果日志。如果建议的更改存在问题,则会引发异常。
以下示例显示了重新启动集群的试运行,myCluster将主集群设置为在端口 4001 上运行的本地成员,以及它返回的日志消息:
JS > var cluster = dba.rebootClusterFromCompleteOutage("myCluster",{primary: "127.0.0.1:4001", dryRun: true})
NOTE: dryRun option was specified. Validations will be executed, but no changes will be applied.
Cluster instances: '127.0.0.1:4000' (OFFLINE), '127.0.0.1:4001' (OFFLINE), '127.0.0.1:4002' (OFFLINE)
Switching over to instance '127.0.0.1:4001' to be used as seed.
dryRun finished.
ClusterSet 和 ReplicaSet 的注意事项
rebootClusterFromCompleteOutage执行以下检查,如果集群不满足要求,则会生成警告:
- 确认副本集群未被从 ClusterSet 中强制删除。
- 确认 ClusterSet 的主集群可访问。
- 检查集群中是否存在非查看更改日志事件 (VCLE) 的错误事务。请参阅 分布式恢复的工作原理。
- 确认集群的已执行事务集 (
GTID_EXECUTED) 不为空。
该命令自动将副本集群重新加入 ClusterSet,确保为所有集群成员配置 ClusterSet 复制通道。
交换通信堆栈
您可以在操作期间切换通信堆栈 dba.rebootClusterFromCompleteOutage() 。
例如:
js> dba.rebootClusterFromCompleteOutage("testcluster", {switchCommunicationStack: "mysql"})
从MYSQL协议切换到 XCOM需要额外的网络地址,并且localAddress可能还需要您定义ipAllowList值。
7.8.4 重新扫描集群
如果您在 AdminAPI 命令之外对集群进行配置更改,例如通过手动更改实例的配置来解决配置问题或在实例丢失后,您需要更新 InnoDB 集群元数据,使其与当前的配置相匹配实例。在这些情况下,请使用该 *Cluster*.rescan() 操作,该操作使您能够手动或使用交互式向导更新 InnoDB Cluster 元数据。这 *Cluster*.rescan() 操作可以检测未在元数据中注册的新活动实例并添加它们,或者仍然在元数据中注册的过时实例(不再活动)并将其删除。您可以根据命令找到的实例自动更新元数据,也可以指定要添加到元数据或从元数据中删除的实例地址列表。您还可以更新存储在元数据中的拓扑模式,例如在 AdminAPI 外部从单主模式更改为多主模式之后。
该命令的语法是 *Cluster*.rescan([options])。该options词典支持以下内容:
-
interactive:布尔值,用于在命令执行中禁用或启用向导。控制是否提供提示和确认。默认值等于 MySQL Shell 向导模式,由 指定shell.options.useWizards。 -
addInstances:列出要添加到元数据的新活动实例的连接数据,或 “自动”以自动将丢失的实例添加到元数据。值“ auto ”不区分大小写。- 列表中指定的实例将添加到元数据中,而不提示确认
- 在交互模式下,系统会提示您确认添加未包含在选项中的新发现的
addInstances实例 - 在非交互模式下,选项中未包含的新发现的实例
addInstances会在输出中报告,但不会提示您添加它们
-
removeInstances:列出要从元数据中删除的过时实例的连接数据,或“ auto ”以自动从元数据中删除过时的实例。- 列表中指定的实例将从元数据中删除,且不提示确认
- 在交互模式下,系统会提示您确认删除选项中未包含的过时
removeInstances实例 - 在非交互模式下,选项中未包含的过时实例
removeInstances会在输出中报告,但不会提示您删除它们
-
updateTopologyMode:布尔值,用于指示元数据中的拓扑模式(单主或多主)是否应更新(true)或不更新(false)以匹配集群正在使用的拓扑模式。默认情况下,元数据不更新 (false)。- 如果该值为 ,
true则将 InnoDB Cluster 元数据与组复制使用的当前模式进行比较,并在必要时更新元数据。在 AdminAPI 外部更改集群的拓扑模式后,使用此选项更新元数据。 - 如果该值为,
false则有关集群拓扑模式的 InnoDB Cluster 元数据不会更新,即使它与集群的 Group Replication 组使用的拓扑不同 - 如果未指定该选项,并且元数据中的拓扑模式与集群的 Group Replication 组使用的拓扑不同,则:
- 交互模式下,系统会提示您确认元数据中拓扑模式的更新
- 在非交互模式下,如果集群的 Group Replication 组使用的拓扑与 InnoDB Cluster 元数据之间存在差异,则会报告该差异,并且不会对元数据进行任何更改
- 当元数据拓扑模式更新为匹配组复制模式时,所有实例上的自动增量设置都会更新,如第 7.5.7 节 “InnoDB 集群和自动增量”中所述。
- 如果该值为 ,
-
updateViewChangeUuid:布尔值,用于指示是否应为group_replication_view_change_uuid集群实例上的系统变量生成和设置值。此系统变量为组生成的视图更改事件提供替代 UUID。对于版本 8.0.27 及更高版本的 MySQL Server 实例,对于属于 InnoDB ClusterSet 一部分的 InnoDB Cluster,系统group_replication_view_change_uuid变量是必需的,并且必须在集群中的所有成员服务器上设置为相同的值。从 MySQL Shell 8.0.27 开始,使用以下命令创建的 InnoDB Clusterdba.createCluster()命令获取为所有成员服务器上的系统变量生成和设置的值。在 MySQL Shell 8.0.27 之前创建的 InnoDB Cluster 可能没有设置系统变量,但 InnoDB ClusterSet 创建过程会检查此变量,如果不存在,则会失败并显示警告。默认情况下,
updateViewChangeUuid设置为false,如果未找到系统变量或在任何实例上都不匹配,则会返回一条警告消息,让您知道必须为系统变量设置一个值并重新启动 InnoDB Cluster。如果设置updateViewChangeUuid为true,则重新扫描操作会group_replication_view_change_uuid在所有成员服务器上生成并设置一个值,之后您必须重新启动集群以实施更改。MySQL Shell 8.0.29之前,该选项不可用,*Cluster*.rescan()命令自动生成并设置系统变量值,就像true设置后,需要重新启动集群才能实施更改。重新启动集群后,您可以重试 InnoDB ClusterSet 创建过程。 -
upgradeCommProtocol:布尔值,用于指示组复制通信协议版本是否应升级(true)或不升级(false)到集群中最低 MySQL 版本的实例支持的版本。默认情况下,不升级通信协议版本(false)。MySQL Shell 8.0.26 之前的 AdminAPI 操作会尽可能自动升级,但该过程可能会导致集群延迟。从 MySQL Shell 8.0.26 开始,如果通信协议版本可以升级,导致拓扑更改的 AdminAPI 操作会返回一条消息,您可以使用此选项在合适的时间进行升级。建议升级到组复制通信协议的最高可用版本,以支持最新功能,例如大型事务的消息碎片。有关更多信息,请参阅 设置群组的通信协议版本。- 如果值为 ,
true则组复制通信协议版本将升级到集群中最低 MySQL 版本的实例支持的版本。 - 如果该值为 ,
false则组复制通信协议版本不会升级。
- 如果值为 ,
7.8.5 隔离集群
发生 紧急故障转移后,ClusterSet 各部分之间的事务集存在不同的风险,您必须隔离集群以防止写入流量或所有流量。尽管您主要在属于集群集的集群上使用隔离,但也可以隔离独立集群,使其免受所有流量的影响。
从 MySQL Shell 8.0.28 开始,提供了三种防护操作:
.fenceWrites():停止向 ClusterSet 的主集群写入流量。.unfenceWrites():恢复写入流量。.fenceAllTraffic():隔离集群,使其免受所有流量的影响。
有关更多详细信息,请参阅第 8.9.1 节 “在 InnoDB ClusterSet 中隔离集群”。
7.9 修改或解散InnoDB集群
本节介绍如何将 InnoDB 集群从单主模式更改为多主模式或相反,如何从 InnoDB 集群中删除服务器实例,以及如何解散不再需要的 InnoDB 集群。
- 更改集群的拓扑
- 从 InnoDB 集群中删除实例
- 解散InnoDB集群
更改集群的拓扑
默认情况下,InnoDB集群以单主模式运行,其中集群有一台主服务器接受读和写查询(R/W),集群中的所有其余实例仅接受读查询(R/O) 。当您将集群配置为在多主模式下运行时,集群中的所有实例都是主实例,这意味着它们同时接受读取和写入查询 (R/W)。如果集群的所有实例都运行 MySQL 服务器版本 8.0.15 或更高版本,您可以在集群在线时更改集群的拓扑。在以前的版本中,需要完全解散并重新创建集群才能进行配置更改。 配置在线组,因此您应该遵守配置在线组的规则。
笔记
多主模式被认为是一种高级模式。
通常,当当前主节点意外离开集群(例如由于意外停止)时,单主集群会选择新的主节点。选举过程通常用于选择当前的辅助节点中的哪一个成为新的主要节点。要覆盖选举过程并强制基础组复制组中的特定服务器实例成为新的主实例,请使用该 函数,其中 指定与应成为新主实例的实例的连接。从 MySQL Shell 8.0.29 开始,您可以使用 *Cluster*.setPrimaryInstance(*instance*[, *options*)instancerunningTransactionsTimeout选项可为使用该函数时正在运行的事务添加 0 到 3600 秒之间的超时。当您设置超时时,发出命令后传入的事务将被拒绝。
您可以使用以下操作更改集群在单主和多主之间运行的模式(有时称为拓扑):
*Cluster*.switchToMultiPrimaryMode(),这会将集群切换到多主模式。所有实例都成为初选实例。*Cluster*.switchToSinglePrimaryMode([*instance*]),这会将集群切换到单主模式。如果 *instance指定,则它成为主实例,所有其他实例成为辅助实例。如果instance*未指定,则新的主实例是具有最高成员权重的实例(如果成员权重相同,则为最低 UUID)。
从 InnoDB 集群中删除实例
如果您愿意,您可以随时从集群中删除实例。这可以使用该 方法来完成,如以下示例所示: *Cluster*.removeInstance(*instance*)
mysql-js> cluster.removeInstance('root@localhost:3310')
The instance will be removed from the InnoDB cluster. Depending on the instance
being the Seed or not, the Metadata session might become invalid. If so, please
start a new session to the Metadata Storage R/W instance.
Attempting to leave from the Group Replication group...
The instance 'localhost:3310' was successfully removed from the cluster.
您可以选择传入interactive 选项来控制是否提示您确认从集群中删除实例。在交互模式下,系统会提示您继续删除(或不删除)实例,以防无法访问该实例。该 操作可确保从所有集群成员以及实例本身*cluster*.removeInstance() 的元数据中删除该实例。无法使用此操作删除 InnoDB Cluster 中 ONLINE保持状态的最后一个实例 。ONLINE
当被删除的实例有仍需要应用的事务时,AdminAPI 将等待 MySQL Shell 选项配置的秒数 dba.gtidWaitTimeout以应用事务 (GTID)。MySQL Shell dba.gtidWaitTimeout选项的默认值为 60 秒, 有关更改默认值的信息,请参阅第 13.4 节“配置 MySQL Shell 选项” 。dba.gtidWaitTimeout如果在等待应用事务时达到 定义的 超时值并且该force选项已false定义(或未定义),则会发出错误并中止删除操作。如果超时值定义为 dba.gtidWaitTimeout等待应用事务时到达,并且该force 选项设置为true然后操作继续而不会出现错误并从集群中删除实例。
重要的
仅当您想要忽略任何错误(例如未处理的事务或实例为 ) 并且不打算在集群中重用该实例时,才应force使用 该选项。从集群中删除实例时忽略错误可能会导致实例与集群不同步,从而阻止其稍后重新加入集群。仅当您计划不再将实例与集群一起使用时才使用该 选项,在所有其他情况下,您应始终尝试恢复实例,并且仅在实例可用且运行状况良好(即状态为 )时将其删除 。 *Cluster*.removeInstance(*instance*)``UNREACHABLE``force``ONLINE
解散InnoDB集群
要解散 InnoDB 集群,您需要连接到读写实例(例如单主集群中的主实例),然后使用该 *Cluster*.dissolve() 命令。这将删除与集群关联的所有元数据和配置,并禁用实例上的组复制。不会删除实例之间复制的任何数据。
重要的
没有办法撤销集群的解散。要再次创建它,请使用dba.createCluster().
该 *Cluster*.dissolve() 操作只能配置 ONLINE可访问的实例。如果您发出的成员无法联系到集群的成员 *Cluster*.dissolve() 命令您必须决定如何进行溶解操作。如果您有机会重新加入集群中被识别为缺失的任何实例,强烈建议您取消溶解操作并首先使缺失的实例重新联机,然后再继续溶解操作。这确保了所有实例都可以正确更新其元数据,并且不会出现裂脑情况。但是,如果无法访问的集群中的实例已永久离开集群,则只能强制执行溶解操作,这意味着丢失的实例将被忽略,只有在线实例会受到该操作的影响。
警告
强制溶解操作忽略集群实例可能会导致在溶解操作期间无法访问的实例继续运行,从而产生裂脑情况的风险。仅当您确定实例不可能再次联机时,才强制执行溶解操作来忽略丢失的实例。
在交互模式下,如果在溶解操作期间无法访问集群成员,则会显示交互提示,例如:
mysql-js> Cluster.dissolve()
The cluster still has the following registered instances:
{
"clusterName": "testCluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "ic-1:3306",
"label": "ic-1:3306",
"role": "HA"
},
{
"address": "ic-2:3306",
"label": "ic-2:3306",
"role": "HA"
},
{
"address": "ic-3:3306",
"label": "ic-3:3306",
"role": "HA"
}
]
}
}
WARNING: You are about to dissolve the whole cluster and lose the high
availability features provided by it. This operation cannot be reverted. All
members will be removed from the cluster and replication will be stopped,
internal recovery user accounts and the cluster metadata will be dropped. User
data will be maintained intact in all instances.
Are you sure you want to dissolve the cluster? [y/N]: y
ERROR: The instance 'ic-2:3306' cannot be removed because it is on a '(MISSING)'
state. Please bring the instance back ONLINE and try to dissolve the cluster
again. If the instance is permanently not reachable, then you can choose to
proceed with the operation and only remove the instance from the Cluster
Metadata.
Do you want to continue anyway (only the instance metadata will be removed)?
[y/N]: y
Instance 'ic-3:3306' is attempting to leave the cluster... Instance 'ic-1:3306'
is attempting to leave the cluster...
WARNING: The cluster was successfully dissolved, but the following instance was
skipped: 'ic-2:3306'. Please make sure this instance is permanently unavailable
or take any necessary manual action to ensure the cluster is fully dissolved.
在此示例中,集群由三个实例组成,其中一个在发出溶解时处于离线状态。错误被捕获,您可以选择如何继续。在这种情况下,丢失的ic-2实例将被忽略,并且可访问的成员的元数据将被更新。
当 MySQL Shell 以非交互模式运行时,例如运行批处理文件时,您可以 *Cluster*.dissolve() 使用该force选项配置操作的行为。要强制溶解操作忽略任何无法访问的实例,请发出:
mysql-js> Cluster.dissolve({force: true})
任何可以访问的实例都会从集群中删除,而任何无法访问的实例都会被忽略。本节中有关强制从集群中删除丢失实例的警告同样适用于这种强制溶解操作的技术。
您还可以使用interactive带有操作的选项 *Cluster*.dissolve() 来覆盖 MySQL Shell 运行的模式,例如在运行批处理脚本时显示交互式提示。例如:
mysql-js> Cluster.dissolve({interactive: true})
MySQL Shell选项配置 在从集群中删除目标实例之前操作等待应用集群事务的dba.gtidWaitTimeout时间 ,但前提是目标实例是. 如果在等待将集群事务应用于任何要删除的实例时达到超时,则会发出错误,除非使用了force: true,这会在这种情况下跳过错误。 *Cluster*.dissolve()``ONLINE
笔记
发出 后cluster.dissolve(),分配给该 *Cluster*对象的任何变量都不再有效。
7.10 升级InnoDB集群
- 7.10.1 InnoDB集群升级
- 7.10.2 InnoDB集群升级故障排除
本节介绍如何升级集群。升级 InnoDB 集群的大部分过程包括以与升级组复制中记录的相同方式升级实例 。本节重点介绍升级 InnoDB Cluster 的其他注意事项。在开始升级之前,您可以使用 MySQL Shell 第 11.1 节 “升级检查器实用程序”来验证实例是否已准备好升级。
重要的
由于元数据查询中出现错误,MySQL Shell 8.0.27 无法用于管理运行 MySQL Server 8.0.25 的 InnoDB Cluster。要解决此问题,请在 InnoDB 集群成员实例上将 MySQL Server 升级到 8.0.26 或 8.0.27 版本,然后再将 MySQL Shell 8.0.27 与集群一起使用。该问题将在 MySQL Shell 8.0.28 中得到修复。
从版本 8.0.19 开始,如果您尝试针对集群引导 MySQL Router 并且发现元数据版本为 0.0.0,这表明元数据升级正在进行中,并且引导失败。等待元数据升级完成,然后再尝试再次引导。当MySQL Router正常运行(不是引导)并且发现元数据版本为0.0.0(正在进行升级)时,MySQL Router不会继续刷新它即将开始的元数据。相反,MySQL Router 继续使用它缓存的最后一个元数据。所有现有的用户连接都会得到维护,并且任何新连接都会根据缓存的元数据进行路由。当元数据版本不再是 0.0.0 时,元数据刷新将重新启动。在常规(非引导)模式下,MySQL Router 使用版本 1.xx 和 2.xx 的元数据。版本可以在 TTL 刷新之间更改。此更改可确保升级集群时路由继续进行。
尽管集群中可能有运行多个 MySQL 版本的实例,例如版本 5.7 和 8.0。不建议长期使用这种混合物。例如,在使用不同版本的集群中,运行5.7版本的实例离开集群,然后使用MySQL Clone进行恢复操作,运行较低版本的实例无法再加入集群,因为权限成为要求 BACKUP_ADMIN。运行具有多个版本的集群旨在作为一种临时情况,以帮助从一个版本迁移到另一个版本,不适合长期使用。
7.10.1 InnoDB集群升级
要升级 InnoDB Cluster 中的服务器实例,请完成以下步骤:
- 升级MySQL路由器。
- 升级 MySQL Shell。
- 升级MySQL服务器。
- 升级后状态检查。
检查已安装的二进制文件的版本:
- ****mysqlrouter –version****:检查安装的 MySQL Router 的版本。
- ****mysqlsh –version****:检查安装的 MySQL Shell 版本。
- ****mysqld –version****:检查安装的 MySQL 服务器的版本。
升级 MySQL 路由器。
要升级 MySQL Router,请完成以下步骤:
-
停止 MySQL 路由器。
在 Unix 系统上,如果您使用了可选的 引导选项,则会在您引导 路由器
--directory时选择的位置创建一个独立的安装,其中包含所有生成的目录和文件 。这些文件包括. 导航到该目录并发出以下命令:stop.sh./stop.sh
在 Microsoft Windows 上,如果您使用了可选的 – bootstrap 选项,则会在您引导 路由器
-directory时选择的位置创建一个独立的安装,其中包含所有生成的目录和文件 。这些文件包括. 导航到该目录并发出以下命令:stop.ps1.\stop.ps1
或者在 Linux 系统上使用
systemd,通过发出以下命令停止 MySQL Router 服务:systemctl stop mysqlrouter.service
否则,杀死关联的mysqlrouter进程的 进程 ID (PID)。
-
获取并安装最新版本的 MySQL Router。
-
启动 MySQL 路由器。
在 Unix 系统上,如果您使用可选的 –
-directorybootstrap 选项,则会在您选择的位置创建一个独立的安装,其中包含所有生成的目录和文件。这些文件包括start.sh. 导航到该目录并发出以下命令:./start.sh
如果新路由器的路径已更改,则必须更新
start.shshell 脚本以反映该路径。#!/bin/bash
basedir=/tmp/myrouter
ROUTER_PID=$basedir/mysqlrouter.pid /usr/bin/mysqlrouter -c $basedir/mysqlrouter.conf &
disown %-
如果您手动升级 MySQL Router,而不是使用包管理,则可以更新
basedir=. 如果再次引导路由器,start.sh则会重新生成 shell 脚本。或者在 Linux 系统上使用
systemd,通过发出以下命令启动 MySQL Router 服务:systemctl start mysqlrouter.service
在 Microsoft Windows 上,如果您使用了可选的 –
-directorybootstrap 选项,则会在您选择的位置创建一个独立的安装,其中包含所有生成的目录和文件。这些文件包括start.ps1. 导航到该目录并发出以下命令:.\start.ps1
使用新的路由器二进制文件启动 MySQL Router 时,通过发出以下命令检查路由器的版本是否升级:
mysqlrouter --version
升级 MySQL Shell
通过安装新的二进制文件并停止和启动 MySQL Shell 来升级 MySQL Shell:
-
获取并安装最新版本的 MySQL Shell。
-
通过发出以下命令来停止并退出 MySQL Shell:
\q
-
通过发出以下命令从命令行重新启动 MySQL Shell:
mysqlsh
-
升级 InnoDB集群元数据:
- 要升级 InnoDB 集群的元数据,请将 MySQL Shell 的全局会话连接到您的集群,并使用该
dba.upgradeMetadata()操作将集群的元数据升级到新的元数据。
元数据升级
如果集群已使用最新版本,元数据升级可能不会执行任何操作。
- 要升级 InnoDB 集群的元数据,请将 MySQL Shell 的全局会话连接到您的集群,并使用该
升级MySQL服务器
通过在升级主实例之前升级所有辅助实例来升级 MySQL Server。
升级 MySQL 服务器是可选的
升级 MySQL 服务器是可选的。服务器升级比升级 MySQL Shell 和 MySQL Router 产生的影响更大。另外,你应该始终将 MySQL Shell 和 MySQL Router 保持在最新版本,即使服务器不是;对于 InnoDB Cluster 和 ReplicaSet 来说也是如此。
-
通过发出以下命令之一停止 MySQL 服务器:
-
如果 MySQL 服务器使用 systemd问题:
systemctl stop mysqld
-
如果 MySQL 服务器正在使用 init.d问题:
/etc/init.d/mysql stop
-
如果MySQL Server正在使用 服务问题:
service mysql stop
-
如果您在 Microsoft Windows 上部署 MySQL Server 问题:
mysqladmin -u root -p shutdown
-
-
获取并安装最新版本的 MySQL Server。
-
通过发出以下命令之一启动 MySQL 服务器:
-
如果 MySQL 服务器使用 systemd问题:
systemctl start mysqld
-
如果 MySQL 服务器正在使用 init.d问题:
/etc/init.d/mysql start
-
如果MySQL Server正在使用 服务问题:
service mysql start
-
如果您在 Microsoft Windows 上部署 MySQL Server 问题:
mysqld
-
-
当所有辅助实例升级后,升级主实例以完成升级过程。
升级后状态检查
升级 MySQL Router 后,MySQL Shell 和 MySQL Server 都会升级:
- 通过发出 来 检查集群
.status()。有关 的更多信息.status(),请参阅 使用 检查集群的状态Cluster.status()。 - 解决任何
clusterErrors``statusText操作返回的 问题.status()。
这些命令允许您检查升级是否成功或者是否需要完成任何其他步骤。
笔记
额外的步骤取决于;您要跳过多少个版本、要升级哪个版本以及要从哪个版本开始。
-
通过发出 来检查每个 InnoDB Cluster 的状态
.status()。在以下示例中,
.status({extended: true})用于提供有关集群状态的更详细信息,返回两个问题:mysqlsh> .status({extended: true});
{
"clusterName": "MyCluster",
"defaultReplicaSet": {
"GRProtocolVersion": "8.0.16",
"groupName": "459ec434-8926-11ec-b8c3-02001707f44a",
"groupViewChangeUuid": "AUTOMATIC",
"groupViewId": "16443558036060755:13",
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"example-el7-1644251369:33311": {
"address": "example-el7-1644251369:33311",
"applierWorkerThreads": 4,
"fenceSysVars": [],
"instanceErrors": [
"NOTE: instance server_id is not registered in the metadata.
Use cluster.rescan() to update the metadata.",
"NOTE: The required parallel-appliers settings are not enabled on the instance.
Use dba.configureInstance() to fix it."
],
"memberId": "247131ab-8926-11ec-850b-02001707f44a",
"memberRole": "PRIMARY",
"memberState": "ONLINE",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.28"
},
"example-el7-1644251369:33314": {
"address": "example-el7-1644251369:33314",
"applierWorkerThreads": 4,
"fenceSysVars": [],
"instanceErrors": [
"NOTE: instance server_id is not registered in the metadata.
Use cluster.rescan() to update the metadata.",
"NOTE: The required parallel-appliers settings are not enabled on the instance.
Use dba.configureInstance() to fix it."
],
"memberId": "303dcfa7-8926-11ec-a6e5-02001707f44a",
"memberRole": "PRIMARY",
"memberState": "ONLINE",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.28"
},
"example-el7-1644251369:33317": {
"address": "example-el7-1644251369:33317",
"applierWorkerThreads": 4,
"fenceSysVars": [],
"instanceErrors": [
"NOTE: instance server_id is not registered in the metadata.
Use cluster.rescan() to update the metadata.",
"NOTE: The required parallel-appliers settings are not enabled on the instance.
Use dba.configureInstance() to fix it."
],
"memberId": "3bb2592e-8926-11ec-8b6f-02001707f44a",
"memberRole": "PRIMARY",
"memberState": "ONLINE",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.28"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "example-el7-1644251369:33311",
"metadataVersion": "2.1.0"
}
.status({extended: true})显示有关集群的更多详细信息。在本例中,我们使用布尔值true,它相当于.status({'extended':1})。有关更多信息,请参阅 使用 检查集群的状态Cluster.status()。 -
解决操作返回的任何错误
.status({extended:1})。在此示例中,
instanceErrors建议在此升级中,我们应该 对集群中的每个成员 发出.rescan()和 :dba.configureInstance()...
"NOTE: instance server_id is not registered in the
metadata. Use .rescan() to update the metadata.",
"NOTE: The required parallel-appliers settings are not
enabled on the instance. Use dba.configureInstance() to fix it."
...
该
.rescan()操作使您能够重新扫描集群以查找新的和过时的组复制实例,以及所用拓扑模式的更改。有关更多信息,请参阅 重新扫描集群。mysqlsh> .rescan();
Rescanning the cluster...Result of the rescanning operation for the 'MyCluster1' cluster:
{
"name": "MyCluster1",
"newTopologyMode": null,
"newlyDiscoveredInstances": [],
"unavailableInstances": [],
"updatedInstances": []
}
该
dba.configureInstance()函数检查使实例能够用于 InnoDB Cluster 使用所需的所有设置。有关更多信息,请参阅 配置生产实例以供 InnoDB 集群使用。在此示例中,我们
dba.configureInstance()对 InnoDB 集群中的每个成员发出问题,以确保在实例上启用所需的并行应用程序设置:mysqlsh> dba.configureInstance('cladmin:cladminpw@localhost:33311')
The instance 'example-el7-1644251369:33311' belongs to an InnoDB Cluster.
Configuring local MySQL instance listening at port 33311 for use in an InnoDB cluster...This instance reports its own address as ^[[1mexample-el7-1644251369:33311^[[0m
Clients and other cluster members will communicate with it through this address by default.
If this is not correct, the report_host MySQL system variable should be changed.applierWorkerThreads will be set to the default value of 4.
^[[36mNOTE: ^[[0mSome configuration options need to be fixed:
+----------------------------------------+---------------+----------------+----------------------------+
| Variable | Current Value | Required Value | Note |
+----------------------------------------+---------------+----------------+----------------------------+
| binlog_transaction_dependency_tracking | COMMIT_ORDER | WRITESET | Update the server variable |
+----------------------------------------+---------------+----------------+----------------------------+Configuring instance...
The instance 'example-el7-1644251369:33311' was configured to be used in an InnoDB cluster.
有关集群升级故障排除的信息,请参阅 InnoDB 集群升级故障排除。
7.10.2 InnoDB集群升级故障排除
本节介绍升级过程中的故障排除。
处理主机名更改
MySQL Shell 使用提供的连接参数的主机值作为用于 AdminAPI 操作的目标主机名,即在元数据中注册实例(对于 和dba.createCluster()操作 *Cluster*.addInstance() )。但是,用于连接参数的实际主机可能 hostname与组复制使用或报告的主机不匹配,组复制在定义系统变量时使用系统变量的值report_host(换句话说,它不是 ),否则使用NULL的值 hostname。因此,AdminAPI 现在遵循相同的逻辑在元数据中注册目标实例,并将其作为默认值 group_replication_local_address 实例上的变量,而不是使用实例连接参数中的主机值。当 report_host 变量设置为空时,组复制对主机使用空值,但 AdminAPI(例如在dba.checkInstanceConfiguration()、 dba.configureInstance()、 dba.createCluster()等命令中)将主机名报告为所使用的值,这与组复制报告的值不一致。如果为系统变量设置空值 report_host,则会生成错误。(错误#28285389)
对于使用 8.0.16 之前的 MySQL Shell 版本创建的集群,尝试从使用 8.0.16 或更高版本执行的完全中断中重新启动集群会导致此错误。这是由于元数据值与实例报告的report_host 或值不匹配造成的。hostname解决方法是:
-
确定哪个实例是 “种子”,换句话说,具有最新 GTID 集的实例。该
dba.rebootClusterFromCompleteOutage()操作检测实例是否是种子,如果当前会话未连接到最新实例,则该操作会生成错误。 -
将系统变量设置
report_host为存储在目标实例的元数据架构中的值。该值是hostname:port创建集群时实例定义中使用的对。该值可以通过查询表来查阅mysql_innodb_cluster_metadata.instances。例如,假设使用以下命令序列创建集群:
mysql-js> \c clusterAdmin@localhost:3306
mysql-js> dba.createCluster("myCluster")
因此,存储在元数据中的主机名值为 “ localhost ”,因此 必须在种子上
report_host设置为“ localhost ” 。 -
仅使用种子实例重新启动集群。在交互式提示处,不要将其余实例添加到集群中。
-
用于
*Cluster*.rescan()将其他实例添加回集群。 -
从集群中删除种子实例
-
在种子实例上停止 mysqld 并删除强制
report_host设置(步骤 2),或将其替换为之前存储在元数据值中的值。 -
重新启动种子实例并将其添加回集群
*Cluster*.addInstance()
这样可以将集群顺利、完整地升级到最新的 MySQL Shell 版本。另一种可能性(取决于用例)是简单地设置 report_host所有集群成员的值,以匹配集群创建时在元数据模式中注册的内容。











![持续集成之代码质量管理Sonar [三]](https://img.mryunwei.com/uploads/2023/05/20230504025442831.png)