

系统开机牵扯到:“我是谁,我从哪里来,要到哪里去”的问题。在冰冷的硬件电路板上死气沉沉,突然一声霹雳,电源键被按下了,从此世界开始有了生机。首先就是硬件上电过程,之后就是固件软件的运行,最后就是操作系统例如Linux的运行。这其中需要涉及一系列的技术,本篇文章尽可能的去介绍。
1. 硬件上电

如上图的一个电路板,连接好12V电源后,手动拨动开关到供电的位置,这个时候会发生什么?
首先就是供电芯片例如PMIC,会对电源轨(按照功能和电压值区分的group)按照设计的顺序(Logical)进行供电,这时候各个硬件器件就来电了。具体可以查看芯片手册里面有说明,需要硬件工程师根据电路板的需求和器件用电量进行设计。
然后时钟模块这时候也开始工作了,为什么需要时钟?这就像心跳,要想CPU工作一次,就需要给一次电压电流,然后拿到计算结果,进行下一次的计算就需要再给一次电压电流。时钟就周期的提供电压电流,然后CPU就有了频率,当然主频越高干活越快。给SoC上的核心通过PLL给各个硬件子系统提供了clock后,这时候就需要一个开关核心(CPU/MCU),然后这个核心就开始工作了,这个开关就是复位信号。
某一个CPU或者MCU核会作为天选之子先硬件直接启动,启动后运行其上的软件,在软件里面控制其他核的复位,从而拉起来其他核心运行。这个天选之子一般在没有M核(SCP)的系统里面就是A核。
有此可见让一个核心工作起来的核心供应就是电压和时钟。除了天选之子,其他核心的启动都是由软件来控制的了。
2. ATF运行

提到ATF就有一个SecureBoot的概念,为了防止黑客篡改程序,什么样的程序最安全?答案就是存放在ROM里面的,不可改变,除非你把这个ROM芯片从板子上拆下来,换上自己的越狱。对于现代SoC,这个ROM做到芯片内部了,没法拆了,只能认命,防刷机神器啊。
这里扯一个话题:水货。什么是水货,首先从水路来的,水路就是海外来的,由于世界各国的消费水平,关税,地方保护等差异比较大,导致在世界上各国销售的电子产品价格差异很大,我们常说的日版iPhone,港版iPhone等价格比国内的低很多,还有各国的运营商的网络制式也不一样,一般销往某个国家的电子产品的版本都需要进行软件定制,然后售价不一样。这里面有个巨大的商机,就是明明硬件一模一样,为啥有点地方卖的贵,可以把便宜的地方的货拿来贵的地方卖,当倒爷啊。能直接用还好,但是大多面临软件版本不一样的问题,这也难不倒,我可以刷机啊,这就是水货了吧。往小了说比如一个芯片供应商,给客户A和B供货,价钱也会不一样,例如A企业风口行业效益好暴利就卖贵一点,B企业传统行业效益不一般贵了买不起,那也得养着啊,蚊子少但是多了也是肉。这里面肯定要防着企业A通过B拿货,或者企业B拿货后转卖了。SecureBoot就是这么现实的需求下诞生的,别扯什么黑客,就是分钱分的不对,这个糟老头,坏的很。

之前的文章:ARM ATF入门-安全固件软件介绍和代码运行里面有固件启动的流程图和开源代码。关于SecureBoot就是BL1 ROM固件里面存的有BL2的秘钥,BL2如果被篡改就不加载,那就不能开机了。同样这样一级一级的
BL1–>BL2–>BL31–>BL32–>BL33–>Linux,任何一个固件和操作系统都改变不了,一环出错就启动不起来,彻底把软件绑定死,不能刷机了。
BL1阶段
最初ROM中的BL1开始运行,主要初始化并读取启动pin引脚,启动介质为UFS,继续初始化UFS pad后,从UFS加载BL2程序到RAM,并验签启动(BL2的验签是通过软件验签实现)
BL2阶段
BL2开始运行,加载并软件验签HSM后启动HSM。(提前设置好HSM时钟or 默认时钟);
等待HSM启动完成后,就可以使用HSM验签。
加载验签其他fimware,例如SoC里面集成的AI模块,NPU、ISP等
BL2通过访问CRU设置DDR时钟,执行DDR初始化,并运行DDR training后,DDR可被正常访问;
BL2加载BL31、BL32、BL33并运行BL31
BL31阶段
等待PMU初始化完成,PMU接管对时钟复位的操作;
BL31其他初始化
BL31作为EL3最后的安全堡垒,它不像BL1和BL2是一次性运行的。如它的runtime名字暗示的那样,它通过SMC指令为Non-Secure持续提供设计安全的服务,在Secure World和Non-Secure World之间进行切换。它的主要任务是找到BL32,验签,并运行BL32。
BL32
BL32是安全OS,是运行时,运行时可以独享系统所有的资源。BL32和Linux同一时刻只能一个运行,是两个操作系统,可以进行切换。为什么BL31也是运行时,但是BL31不是OS,因为BL31虽然在某一时刻独占系统资源,也是运行时,但是其没有调度等OS的特点,只是一个运行时服务。
一般在BL32会运行OPTee OS + 安全app,它是一个可信安全的OS运行在EL1并在EL0启动可信任APP(如指纹信息,移动支付的密码等),并在Trust OS运行完成后通过SMC指令返回BL31,BL31切换到Non-Seucre World继续执行BL33。一个开源代码:github.com/OP-TEE
BL33也就是Uboot阶段
Uboot不是运行时,也就是完成它自己的使命就再也不工作了。U-Boot可以提供引导、配置硬件、加载内核、初始化设备等功能,使得嵌入式系统能够正常启动并运行。
Linux阶段
PMU及CLock、Power Domain初始化;
NPU等固件交互驱动初始化
其他设备初始化
根文件系统加载
上层服务加载运行
下面介绍两个经典的方案,一个是NXP的一个是ARM SCP的
NXP SCU与SCFW固件方案
以imx8qm平台为例,imx8qm引入了操纵资源分配、电源、时钟以及 IO 配置和复用的新概念。由于这种新芯片的架构复杂性,系统中添加了一个系统控制器单元 (SCU)。SCU 是 Arm Cortex-M4 内核,是 imx8qm设计中第一个启动的处理器。
为了控制 SCU 的所有功能,NXP创建了SCFW。SCFW 在移植套件中分发。SCFW 的第一个主要步骤是配置 DDR 并启动系统中的所有其他内核。引导流程如下图所示:

imx8qm启动顺序涉及 SCU ROM、SCFW、安全控制器 (SECO) ROM 和 SECO FW:
•复位时,SCU ROM 和 SECO ROM 都开始执行
•SCU ROM 读取启动模式引脚
•SCU ROM 从引导介质加载第一个容器;这个容器总是有SECO FW,使用 NXP 密钥签名
•SECO FW 加载到 SECO 紧耦合存储器 (TCM)
•SCU通过专用 MU 向 SECO ROM 发送消息以验证和运行 SECO FW
•SCU ROM 从引导介质加载第二个容器;此容器始终具有SCFW,并且可以使用客户密钥进行签名
•SCFW加载到 SCU TCM
•然后 SCU ROM 将配置 DDR
•SCU ROM 将启动 SCFW
从这一点开始,SCFW 接管并将任何image加载到 Arm Cortex-M 或 Cortex-A 内核。
ARM SCP固件方案
系统控制处理器(system control processor,简称SCP)一般是一个硬件模块,例如cortex-M0微处理器再加上一些外围逻辑电路做成的功耗控制单元。SCP能够配合操作系统的功耗管理软件或驱动,来完成顶层的功耗控制。
SCP固件是通过ATF中BL2过程加载的,启动过程如下:

ATF的代码这里就不分析了,可以参考下面资料里面的分析:
关于ATF启动的文章(知乎lgjjeff,写的很好):
zhuanlan.zhihu.com/p/520039243
关于BL32 OPTEE的文章:
zhuanlan.zhihu.com/p/553490159
3. Linux启动
估计大多读者还是对Linux有兴趣,这里对代码进行一下详细的分析。

Linux内核启动前系统一直是运行在单CPU Core0上的,之后通过Linux的多核管理机制(smp)依次启动其他核心。上图为Linux 多核启动流程图,
EL1运行的Linux
arm64多核启动方式基本都是PSCI,他不仅可以启动从处理器,还可以关闭,挂起等其他核操作
核心为:主处理器给从处理器一个启动地址,然后从处理器从这个地址执行指令
3.1 内核启动start_kernel
开机的时候会执行start_kernel()函数,在init/main.c中
void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();//获取当前cpu编号
debug_objects_early_init();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();//引导cpu初始化 设置引导cpu的位掩码 online active present possible都为true
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
rest_init();
3.2 平台启动setup_arch
在arch/arm64/kernel/setup.c中,会执行setup_arch函数
void __init setup_arch(char **cmdline_p)
{
if (acpi_disabled)
unflatten_device_tree();//扫码设备树,转换成device_node
if (acpi_disabled)//不支持acpi
psci_dt_init();//drivers/firmware/psci.c(psci主要文件) psci初始化 解析设备树 寻找psci匹配的节点
smp_init_cpus(); //初始化cpu的ops函数

__cpu_method_of_table里面存的有各种方法结构体如下:
struct of_cpu_method {
const char *method;
const struct smp_operations *ops;
};
根据enable-method找到对应的ops处理函数
static int __init set_smp_ops_by_method(struct device_node *node)
{
const char *method;
struct of_cpu_method *m = __cpu_method_of_table;
if (of_property_read_string(node, "enable-method", &method))
return 0;
for (; m->method; m++)
if (!strcmp(m->method, method)) {
smp_set_ops(m->ops);
return 1;
}
return 0;
}
有一个宏去定义这些电源管理方式:
#define CPU_METHOD_OF_DECLARE(name, _method, _ops)
static const struct of_cpu_method _cpu_method_of_table##name
__used __section(__cpu_method_of_table)
= { .method = _method, .ops = _ops }
每个厂家可以根据自己的情况定义cpu method,例如arch/arm/mach-rockchip/platsmp.c
smp_operations,系统启动过程中,Linux kernel提供了smp boot实现的框架,要实现smp boot,先要填充好smp_operations这个结构体,smp_operations结构体定义如下所示:
static const struct smp_operations rockchip_smp_ops __initconst = {
.smp_prepare_cpus = rockchip_smp_prepare_cpus,
.smp_boot_secondary = rockchip_boot_secondary,
#ifdef CONFIG_HOTPLUG_CPU
.cpu_kill = rockchip_cpu_kill,
.cpu_die = rockchip_cpu_die,
#endif
};
CPU_METHOD_OF_DECLARE(rk3036_smp, "rockchip,rk3036-smp", &rk3036_smp_ops);
CPU_METHOD_OF_DECLARE(rk3066_smp, "rockchip,rk3066-smp", &rockchip_smp_ops);
SMP(Symmetric Multi-Processing),对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。像双至强,也就是我们所说的二路,这是在对称处理器系统中最常见的一种(至强MP可以支持到四路,AMD Opteron可以支持1-8 路)。
ops的定义为:
struct smp_operations {
#ifdef CONFIG_SMP
/*
* Setup the set of possible CPUs (via set_cpu_possible)
*/
void (smp_init_cpus)(void);
/
* Initialize cpu_possible map, and enable coherency
*/
void (*smp_prepare_cpus)(unsigned int max_cpus);
/*
* Perform platform specific initialisation of the specified CPU.
*/
void (*smp_secondary_init)(unsigned int cpu);
/*
* Boot a secondary CPU, and assign it the specified idle task.
* This also gives us the initial stack to use for this CPU.
*/
int (*smp_boot_secondary)(unsigned int cpu, struct task_struct *idle);
#ifdef CONFIG_HOTPLUG_CPU
int (*cpu_kill)(unsigned int cpu);
void (*cpu_die)(unsigned int cpu);
bool (*cpu_can_disable)(unsigned int cpu);
int (*cpu_disable)(unsigned int cpu);
#endif
#endif
};
多核的启动函数调用流程主要如下所示:
start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->smp_init()
在smp_init()中,会通过for_each_present_cpu,让每一个present的cpu wakeup起来。
3.3 CPU初始化smp_init_cpus
smp_init_cpus()会循环调用smp_cpu_setup()
for (i = 1; i cpu_read_ops
->cpu_get_ops
->dt_supported_cpu_ops
->cpu_psci_ops
const struct cpu_operations cpu_psci_ops = {
.name = “psci”,
#ifdef CONFIG_CPU_IDLE
.cpu_init_idle = psci_cpu_init_idle,
.cpu_suspend = psci_cpu_suspend_enter,
#endif
.cpu_init = cpu_psci_cpu_init,
.cpu_prepare = cpu_psci_cpu_prepare,
.cpu_boot = cpu_psci_cpu_boot,
#ifdef CONFIG_HOTPLUG_CPU
.cpu_disable = cpu_psci_cpu_disable,
.cpu_die = cpu_psci_cpu_die,
.cpu_kill = cpu_psci_cpu_kill,
#endif
};
3.4 DTS初始化psci_dt_init
psci_dt_init是解析设备树,设置操作函数


psci节点的详细说明可以参考内核文档:Documentation/devicetree/bindings/arm/psci.txt
可以看到现在enable-method 属性已经是psci,说明使用的多核启动方式是psci, 下面还有psci节点,用于psci驱动使用,method用于说明调用psci功能使用什么指令,可选有两个smc和hvc。其实smc, hvc和svc都是从低运行级别向高运行级别请求服务的指令,我们最常用的就是svc指令了,这是实现系统调用的指令。高级别的运行级别会根据传递过来的参数来决定提供什么样的服务。smc是用于陷入el3(安全), hvc用于陷入el2(虚拟化, 虚拟化场景中一般通过hvc指令陷入el2来请求唤醒vcpu), svc用于陷入el1(系统)。
注:本文只讲解smc陷入el3启动多核的情况。
关于EL3和ATF的介绍:
•armv8将异常等级分为el0 – el3,其中,el3为安全监控器,为了实现对它的支持,arm公司设计了一种firmware叫做ATF(ARM Trusted firmware),下面是atf源码readme.rst文件的一段介绍:
Trusted Firmware-A (TF-A) provides a reference implementation of secure world
software for Armv7-A and Armv8-A_, including a Secure Monitor_ executing
at Exception Level 3 (EL3). It implements various Arm interface standards,
such as:
– The Power State Coordination Interface (PSCI)_
– Trusted Board Boot Requirements (TBBR, Arm DEN0006C-1)
– SMC Calling Convention_
– System Control and Management Interface (SCMI)_
– Software Delegated Exception Interface (SDEI)_
•ATF代码运行在EL3, 是实现安全相关的软件部分固件,其中会为其他特权级别提供服务,也就是说提供了在EL3中服务的手段,我们本文介绍的PSCI的实现就是在这里面,本文不会过多的讲解(注:其实本文只会涉及到atf如何响应服务el1的smc发过来的psci的服务请求,仅此而已,有关ATF(Trustzone)请参考其他资料)。
PSCI初始化流程:
start_kernel() -> setup_arch() -> psci_dt_init() -> psci_0_2_init() -> psci_probe() -> psci_0_2_set_functions()
设备树里面的信息如下里标记的版本是psci-0.2,method是使用smc。
psci {
compatible = “arm,psci-1.2”;
method = “smc”;
};
当前设备启动时,扫描设备树相关信息时打印的PSCI相关的信息如下:

psci_dt_init()函数如下,根据不同的compatible来匹配不同的init函数。drivers/firmware/psci.c中
static const struct of_device_id psci_of_match[] __initconst = {
{ .compatible = “arm,psci”, .data = psci_0_1_init},
{ .compatible = “arm,psci-0.2”, .data = psci_0_2_init},
{ .compatible = “arm,psci-1.0”, .data = psci_0_2_init},
{},
};
int __init psci_dt_init(void)
{
struct device_node *np;
const struct of_device_id *matched_np;
psci_initcall_t init_fn;
np = of_find_matching_node_and_match(NULL, psci_of_match, &matched_np);
if (!np)
return -ENODEV;
init_fn = (psci_initcall_t)matched_np->data;
return init_fn(np);
}
psci_0_2_init() -> get_set_conduit_method() 设置hvc还是smc处理。
psci_0_2_init() -> psci_probe() -> psci_0_2_set_functions()函数会在初始化的时候调用
static void __init psci_0_2_set_functions(void)
{
pr_info(“Using standard PSCI v0.2 function IDsn”);
psci_ops.get_version = psci_get_version;
psci_function_id[PSCI_FN_CPU_SUSPEND] =
PSCI_FN_NATIVE(0_2, CPU_SUSPEND);
psci_ops.cpu_suspend = psci_cpu_suspend;
psci_function_id[PSCI_FN_CPU_OFF] = PSCI_0_2_FN_CPU_OFF;
psci_ops.cpu_off = psci_cpu_off;
psci_function_id[PSCI_FN_CPU_ON] = PSCI_FN_NATIVE(0_2, CPU_ON);
psci_ops.cpu_on = psci_cpu_on; //设置psci操作的开核接口
3.5 系统rest创建kernel_init线程
->rest_init
->kernel_init
->kernel_init_freeable
->smp_prepare_cpus //准备cpu 对于每个可能的cpu 1. cpu_ops[cpu]->cpu_prepare(cpu) 2.set_cpu_present(cpu, true) cpu处于present状态
->do_pre_smp_initcalls //多核启动之前的调用initcall回调
->smp_init //smp初始化 kernel/smp.c 会启动其他从处理器
3.6 SMP初始化smp_init
start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->smp_init()
在smp_init()中,会通过for_each_present_cpu,让每一个present的cpu wakeup起来
->smp_init //kernel/smp.c (这是从处理器启动的函数)
->cpu_up
->do_cpu_up
->_cpu_up
->cpuhp_up_callbacks
->cpuhp_invoke_callback
->cpuhp_hp_states[CPUHP_BRINGUP_CPU]
->bringup_cpu
->__cpu_up //arch/arm64/kernel/smp.c
->boot_secondary
->cpu_ops[cpu]->cpu_boot(cpu)
->cpu_psci_ops.cpu_boot
->cpu_psci_cpu_boot //arch/arm64/kernel/psci.c
46 static int cpu_psci_cpu_boot(unsigned int cpu)
47 {
48 int err = psci_ops.cpu_on(cpu_logical_map(cpu), __pa_symbol(secondary_entry));
49 if (err)
50 pr_err("failed to boot CPU%d (%d)n", cpu, err);
51
52 return err;
53 }
•启动从处理的时候最终调用到psci的cpu操作集的cpu_psci_cpu_boot函数,会调用上面的psci_cpu_on,最终调用smc,传递第一个参数为cpu的id标识启动哪个cpu,第二个参数为从处理器启动后进入内核执行的地址secondary_entry(这是个物理地址)。
•所以综上,最后smc调用时传递的参数为arm_smccc_smc(0xC4000003, cpuid, secondary_entry, arg2, 0, 0, 0, 0, &res)。
•这样陷入el3之后,就可以启动对应的从处理器,最终从处理器回到内核(el3->el1),执行secondary_entry处指令,从处理器启动完成。
•可以发现psci的方式启动从处理器的方式相当复杂,这里面涉及到了el1到安全的el3的跳转,而且涉及到大量的函数回调,很容易绕晕。
cpu_boot的初始化:
见2.2.3中cpu初始化赋值
secondary_entry是执行SMC系统调用返回执行的地址
cpu_on就是psci_cpu_on
见3.4中psci初始化赋值
多核的启动函数调用流程主要如下所示:
start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->smp_init()
在smp_init()中,会通过for_each_present_cpu,让每一个present的cpu wakeup起来,代码如下:
/* Called by boot processor to activate the rest. */
void __init smp_init(void)
{
int num_nodes, num_cpus;
unsigned int cpu;
idle_threads_init();//为非boot cpu创建idle task
cpuhp_threads_init();//为每个cpu创建一个hotplug线程
pr_info("Bringing up secondary CPUs ...n");
//遍历cpu,对没有online的进行online操作
for_each_present_cpu(cpu) {
if (num_online_cpus() >= setup_max_cpus)
break;
if (!cpu_online(cpu))
cpu_up(cpu);
}
num_nodes = num_online_nodes();
num_cpus = num_online_cpus();
//打印当前online的cpu数目
pr_info("Brought up %d node%s, %d CPU%sn",
num_nodes, (num_nodes > 1 ? "s" : ""),
num_cpus, (num_cpus > 1 ? "s" : ""));
/* Final decision about SMT support */
cpu_smt_check_topology();
/* Any cleanup work */
smp_cpus_done(setup_max_cpus);
}
kernel/cpu.c中,cpu_up->do_cpu_up->_cpu_up
cpu_up()调用do_cpu_up()时主要传两个参数,一个cpuid,一个cpu状态,如下所示:
int cpu_up(unsigned int cpu)
{
return do_cpu_up(cpu, CPUHP_ONLINE);
}
EXPORT_SYMBOL_GPL(cpu_up);
而在_cpu_up()中会根据cpu状态通过一个min宏通过与CPUHP_BRINGUP_CPU比较取最小的一个,代码如下:
/* Requires cpu_add_remove_lock to be held */
static int _cpu_up(unsigned int cpu, int tasks_frozen, enum cpuhp_state target)
{
struct cpuhp_cpu_state *st = per_cpu_ptr(&cpuhp_state, cpu);
struct task_struct *idle;
int ret = 0;
cpus_write_lock();
if (!cpu_present(cpu)) {//检查当前cpu是否满足需求
ret = -EINVAL;
goto out;
}
/*
* The caller of do_cpu_up might have raced with another
* caller. Ignore it for now.
*/
if (st->state >= target)
goto out;
if (st->state == CPUHP_OFFLINE) {
/* Let it fail before we try to bring the cpu up */
idle = idle_thread_get(cpu);
if (IS_ERR(idle)) {
ret = PTR_ERR(idle);
goto out;
}
}
cpuhp_tasks_frozen = tasks_frozen;
cpuhp_set_state(st, target);//设置st->target为online
/*
* If the current CPU state is in the range of the AP hotplug thread,
* then we need to kick the thread once more.
*/
if (st->state > CPUHP_BRINGUP_CPU) {
ret = cpuhp_kick_ap_work(cpu);
/*
* The AP side has done the error rollback already. Just
* return the error code..
*/
if (ret)
goto out;
}
/*
* Try to reach the target state. We max out on the BP at
* CPUHP_BRINGUP_CPU. After that the AP hotplug thread is
* responsible for bringing it up to the target state.
*/
target = min((int)target, CPUHP_BRINGUP_CPU);
ret = cpuhp_up_callbacks(cpu, st, target);
out:
cpus_write_unlock();
return ret;
}
而CPUHP_BRINGUP_CPU这些值实在cpuhotplug.h的枚举变量cpuhp_state中枚举出来,列举几个如下所示:
enum cpuhp_state {
CPUHP_OFFLINE,
CPUHP_CREATE_THREADS,
CPUHP_PERF_PREPARE,
从该变量可以看出CPUHP_ONLINE的值是最大的,因此_cpu_up()调用cpuhp_up_callbacks()时传入的target为CPUHP_BRINGUP_CPU。
进入到cpuhp_up_callbacks()后,由于st->state是0,是小于传下来的target的,因此会通过一个while循环,每个cpu都遍历所有满足st->state < CPUHP_BRINGUP_CPU,来进行启动其他cpu的一些准备工作,代码如下所示:
cpuhp_up_callbacks()函数对cpu状态更新,知道target满足状态,如果识别则undo_cpu_up
static int cpuhp_up_callbacks(unsigned int cpu, struct cpuhp_cpu_state *st,
enum cpuhp_state target)
{
enum cpuhp_state prev_state = st->state;
int ret = 0;
while (st->state state++;
ret = cpuhp_invoke_callback(cpu, st->state, true, NULL, NULL);
if (ret) {
st->target = prev_state;
undo_cpu_up(cpu, st);
break;
}
}
return ret;
}
cpuhp_invoke_callback(cpu, st->state, true, NULL, NULL);对应如下:
/ * *
* cpuhp_invoke_callback _为给定状态调用回调函数
* @cpu:调用回调函数的cpu
* @state:执行回调的状态
* @bringup: true,表示应该调用调出回调函数
* @node:对于多实例,为install/remove执行单个条目的回调
* @lastp:对于多实例回滚,请记住我们已经走了多远
*
*从cpu热插拔和状态寄存器机器调用。
* /
static int cpuhp_invoke_callback(unsigned int cpu, enum cpuhp_state state,
bool bringup, struct hlist_node *node,
struct hlist_node **lastp)
{
struct cpuhp_cpu_state *st = per_cpu_ptr(&cpuhp_state, cpu);
struct cpuhp_step *step = cpuhp_get_step(state);
进入到cpuhp_invoke_callback()函数后,首先根据传下来的st->state通过cpuhp_get_step()函数从全局数组cpuhp_bp_states[]中拿到相应的struct cpuhp_step结构变量,因此这里会遍历调用cpuhp_bp_states数组元素里的回调函数
/ * *
* cpuhp_cpu_state—每个cpu热插拔状态存储
* @state:当前cpu的状态
* @target:目标状态
* @thread:热插拔线程的指针
* @should_run:线程应该执行
* @rollback:执行回滚
* @single:单个回调调用
* @bringup:单个回调调出或卸载选择器
* @cb_state:单个回调函数的状态(安装/卸载)
* @result:操作的结果
* @done_up:向任务的颁发者发出信号,以便cpu-up
* @done_down:向cpu-down的进程发出完成信号
* /
cpuhp_get_step()函数获取state全局变量
static struct cpuhp_step *cpuhp_get_step(enum cpuhp_state state)
{
struct cpuhp_step *sp;
sp = cpuhp_is_ap_state(state) ? cpuhp_ap_states : cpuhp_bp_states;
return sp + state;
}
cpuhp_bp_states如下,这是一个状态为下标的数组,整个状态图为:
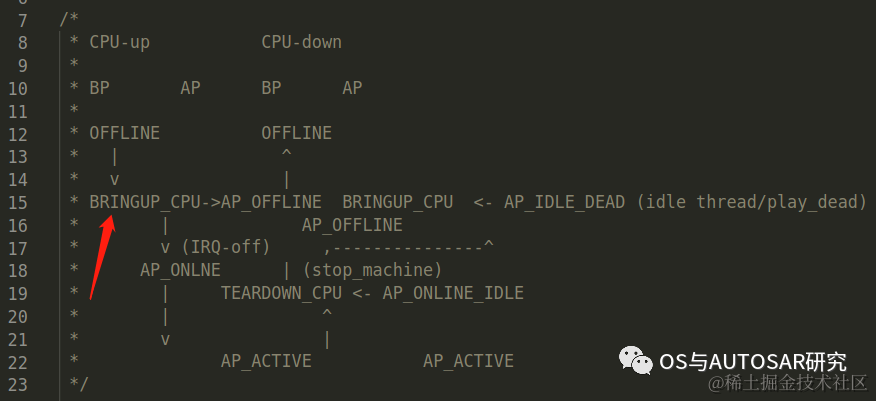
/* Boot processor state steps */
static struct cpuhp_step cpuhp_bp_states[] = {
[CPUHP_OFFLINE] = {
.name = "offline",
.startup.single = NULL,
.teardown.single = NULL,
},
/* Kicks the plugged cpu into life */
[CPUHP_BRINGUP_CPU] = {
.name = "cpu:bringup",
.startup.single = bringup_cpu,
.teardown.single = NULL,
.cant_stop = true,
},
bringup_cpu负责给制定的cpu上电
static int bringup_cpu(unsigned int cpu)
{
struct task_struct *idle = idle_thread_get(cpu);//获取要上电cpu的idle进程
int ret;
/*
* Some architectures have to walk the irq descriptors to
* setup the vector space for the cpu which comes online.
* Prevent irq alloc/free across the bringup.
*/
irq_lock_sparse();
/* Arch-specific enabling code. */
ret = __cpu_up(cpu, idle);
irq_unlock_sparse();
if (ret)
return ret;
return bringup_wait_for_ap(cpu);
}
3.7 PSCI接口psci_cpu_on
->psci_cpu_on()
->invoke_psci_fn()
->__invoke_psci_fn_smc()
-> arm_smccc_smc(function_id, arg0, arg1, arg2, 0, 0, 0, 0, &res) //这个时候x0=function_id x1=arg0, x2=arg1, x3arg2,...
->__arm_smccc_smc()
->SMCCC smc //arch/arm64/kernel/smccc-call.S
-> 20 .macro SMCCC instr
21 .cfi_startproc
22 instr #0 //即是smc #0 陷入到el3
23 ldr x4, [sp]
24 stp x0, x1, [x4, #ARM_SMCCC_RES_X0_OFFS]
25 stp x2, x3, [x4, #ARM_SMCCC_RES_X2_OFFS]
26 ldr x4, [sp, #8]
27 cbz x4, 1f /* no quirk structure */
28 ldr x9, [x4, #ARM_SMCCC_QUIRK_ID_OFFS]
29 cmp x9, #ARM_SMCCC_QUIRK_QCOM_A6
30 b.ne 1f
31 str x6, [x4, ARM_SMCCC_QUIRK_STATE_OFFS]
32 1: ret
33 .cfi_endproc
34 .endm
最终通过22行 陷入了el3中。
3.8 SMC返回secondary_entry
在3.6中进行SMC系统调用的时候,设置了secondary_entry
•smc调用时传递的参数为arm_smccc_smc(0xC4000003, cpuid, secondary_entry, arg2, 0, 0, 0, 0, &res)。
•这样陷入el3之后,就可以启动对应的从处理器,最终从处理器回到内核(el3->el1),执行secondary_entry处指令,从处理器启动完成。
/*
* Secondary entry point that jumps straight into the kernel. Only to
* be used where CPUs are brought online dynamically by the kernel.
*/
ENTRY(secondary_entry)
bl el2_setup // Drop to EL1
bl set_cpu_boot_mode_flag
b secondary_startup
ENDPROC(secondary_entry)
secondary_startup:
/*
* Common entry point for secondary CPUs.
*/
bl __cpu_setup // initialise processor
bl __enable_mmu//使能mmu
ldr x8, =__secondary_switched
br x8
ENDPROC(secondary_startup)
__secondary_switched:
adr_l x5, vectors//设置从处理器的异常向量表
msr vbar_el1, x5
isb //指令同步屏障 保证屏障前面的指令执行完
adr_l x0, secondary_data //获得主处理器传递过来的从处理器数据
ldr x1, [x0, #CPU_BOOT_STACK] // get secondary_data.stack 获得栈地址
mov sp, x1 //设置到从处理器的sp
ldr x2, [x0, #CPU_BOOT_TASK] //获得从处理器的tsk idle进程的tsk结构,
msr sp_el0, x2 //保存在sp_el0 arm64使用sp_el0保存当前进程的tsk结构
mov x29, #0 //fp清0
mov x30, #0 //lr清0
b secondary_start_kernel //跳转到c程序 继续执行从处理器初始化
ENDPROC(__secondary_switched)
secondary_start_kernel
184 * This is the secondary CPU boot entry. We're using this CPUs
185 * idle thread stack, but a set of temporary page tables.
186 */
187 asmlinkage notrace void secondary_start_kernel(void)
188 {
189 u64 mpidr = read_cpuid_mpidr() & MPIDR_HWID_BITMASK;
190 struct mm_struct *mm = &init_mm;
191 unsigned int cpu;
192
193 cpu = task_cpu(current);
194 set_my_cpu_offset(per_cpu_offset(cpu));
195
196 /*
197 ¦* All kernel threads share the same mm context; grab a
198 ¦* reference and switch to it.
199 ¦*/
200 mmgrab(mm); //init_mm的引用计数加1
201 current->active_mm = mm; //设置idle借用的mm结构
202
203 /*
204 ¦* TTBR0 is only used for the identity mapping at this stage. Make it
205 ¦* point to zero page to avoid speculatively fetching new entries.
206 ¦*/
207 cpu_uninstall_idmap();
208
209 preempt_disable(); //禁止内核抢占
210 trace_hardirqs_off();
211
212 /*
213 ¦* If the system has established the capabilities, make sure
214 ¦* this CPU ticks all of those. If it doesn't, the CPU will
215 ¦* fail to come online.
216 ¦*/
217 check_local_cpu_capabilities();
218
219 if (cpu_ops[cpu]->cpu_postboot)
220 cpu_ops[cpu]->cpu_postboot();
221
222 /*
223 ¦* Log the CPU info before it is marked online and might get read.
224 ¦*/
225 cpuinfo_store_cpu(); //存储cpu信息
226
227 /*
228 ¦* Enable GIC and timers.
229 ¦*/
230 notify_cpu_starting(cpu); //使能gic和timer
231
232 store_cpu_topology(cpu); //保存cpu拓扑
233 numa_add_cpu(cpu); ///numa添加cpu
234
235 /*
236 ¦* OK, now it's safe to let the boot CPU continue. Wait for
237 ¦* the CPU migration code to notice that the CPU is online
238 ¦* before we continue.
239 ¦*/
240 pr_info("CPU%u: Booted secondary processor 0x%010lx [0x%08x]n",
241 ¦cpu, (unsigned long)mpidr,
242 ¦read_cpuid_id()); //打印内核log
243 update_cpu_boot_status(CPU_BOOT_SUCCESS);
244 set_cpu_online(cpu, true); //设置cpu状态为online
245 complete(&cpu_running); //唤醒主处理器的 完成等待函数,继续启动下一个从处理器
246
247 local_daif_restore(DAIF_PROCCTX); //从处理器继续往下执行
248
249 /*
250 ¦* OK, it's off to the idle thread for us
251 ¦*/
252 cpu_startup_entry(CPUHP_AP_ONLINE_IDLE); //idle进程进入idle状态
253 }
从处理器启动到内核的时候,他们也需要设置异常向量表,设置mmu等,然后执行各自的idle进程(这些都是一些处理器强相关的初始化代码,一些通用的初始化都已经被主处理器初始化完),当cpu负载均衡的时候会放置一些进程到这些从处理器,然后进程就可以再这些从处理器上欢快的运行。
多核启动涉及到的ATF中的流程,如下图:

ARM平台开机CPU启动流程图
•CPU上电后,只启动了CPU 0,其他核还处在power down状态。
•CPU0会依次执行bootrom->BL2->BL31->BL32->uboot->linux,进入linux内核以后,调用smp接口跟BL31交互,从而将其他核心跑起来。
•BL31运行在EL3,Linux运行在EL1,所有需要使用SMC指令从EL1陷入到EL3,参数传递需要遵循SMCC规范。
具体代码这里不分析了,可以参考之前关机重启文章里面的BL31内容。
Linux启动比较复杂,上面仅从主要的多核启动角度进行了分析。此外还有Clock、power domain相关的一些操作。
clk相关:
linux将时钟相关的硬件模块组织成一个时钟树。根节点一般是晶振,接着是pll(时钟倍频),然后是mux(时钟源选择),后面会有div(时钟分频),最终叶子节点一般是gate(时钟开关),一个例子如下:

clk框架:

Linux为了做好时钟管理,提供了一个时钟管理框架CCF(common clock framework),跟其他框架类似由三部分组成:
屏蔽底层硬件操作:向上提供设置或者策略接口,屏蔽底层驱动的硬件操作,提供操作clocks的通用接口,比如:clk_enable/clk_disable,clk_set_rate/clk_get_rate等,供其他consumer使用时钟的gate、调频等功能。consumer使用clock framework提供的接口之前要先获取clk句柄,通过如下接口获取:devm_clk_get/clk_get/of_clk_get。
· 提供注册接口:向下给clock驱动提供注册接口,将硬件(包括晶振、PLL、MUX、DIVIDER、GATE等)相关的clock控制逻辑封装成操作函数集,交给底层的clock驱动实现。
· 时钟管理核心逻辑:中间是clock控制的通用逻辑,和硬件无关。
clk初始化:

power domain相关:
SOC是由多功能模块组成的一个整体,对于工作在相同电压且功能内聚的功能模块,可以划为一个逻辑组,这样的一个逻辑组就是一个电源域。SOC上众多电源域组成了一个电源域树,他们之间存在着相互的约束关系,子电源域打开前,需要父电源域打开,父电源域下所有子电源域关闭,父电源域才能关闭。
pd框架:

power domain framework主要管理power domain的状态,为使用它的上游驱动、框架或者用户空间所使用的文件操作节点,提供功能接口,对下层的power domain hardware的开关操作进行封装,然后内部的逻辑,实现具体的初始化、开关等操作。
•对底层power domain硬件的操作
○对power domain hw的开启操作,包括开钟、上电、解复位、解除电源隔离等操作的功能封装;
○对power domain hw的关闭操作,包括关钟、断电、复位、做电源隔离等操作的功能封装;
•内部逻辑实现
○通过dts描述power domain框架的设备节点,并描述每个power domain节点。提供出一个power domain framework的设备节点,及每个power domain子设备的节点,并指定power-domain-ccell = ,这样可以通过power domain framework的设备及power domain的编号查找具体的power domain;
○实现dts解析逻辑,获取power domain的配置信息,并通过初始化函数对每个power domain进行初始化,所有的power domain统一的放在一个全局链表中,将power domain下所有的设备,放到其下的一个设备链表中;
○为runtime pm、系统休眠唤醒等框架,注册相应的回调函数,并实现具体的回调函数对应的power domain的开关函数;
后记:
Linux启动中涉及的模块很多,每一个小部分其实都可以单独写一篇文章,后续继续从电源管理角度挑出来这些部分进行说明。对于涉及的代码,我基本都是自己打log去看验证真伪的,实践才能记住,多实践才能记的时间长。
根据经验间隔1年左右的工作领域知识就会忘记差不多了,笔者工作十多年,不停的换技术方向,可以说技术细节全都忘记了,能记住的基本就是当时好像看了什么书,看了什么视频学习的,当时学到什么程度了,要再开始干不迷糊,能准确的找到资料,能描述出来技术框架,不迷茫。这里也是多写博客的重要性,好记性不如烂笔头,等若干年后,可能技术细节都忘记了,也看不懂了,但是还能提醒你忘记了什么,不然好似完全没发生过,你都不知道自己忘记了什么,生命终被时间冲刷的了无痕迹。
“啥都懂一点,啥都不精通,
干啥都能干,干啥啥不是,
专业入门劝退,堪称程序员杂家”。
后续会继续更新,纯干货分析,欢迎分享给朋友,欢迎评论交流!
 微信扫一扫 ,关注该公众号
微信扫一扫 ,关注该公众号











